 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGREAT: Geometry-Intention Collaborative Inference for Open-Vocabulary 3D Object Affordance Grounding
Paper and Code
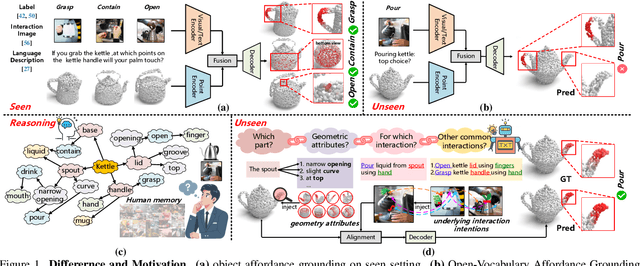
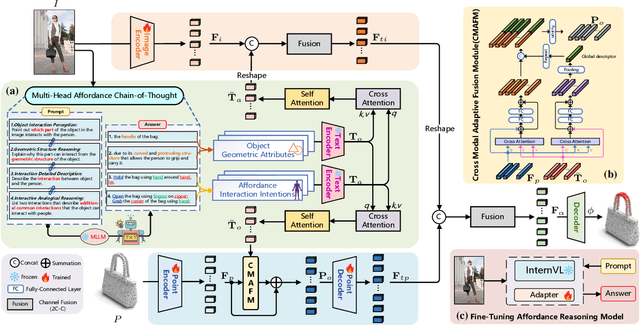

Open-Vocabulary 3D object affordance grounding aims to anticipate ``action possibilities'' regions on 3D objects with arbitrary instructions, which is crucial for robots to generically perceive real scenarios and respond to operational changes. Existing methods focus on combining images or languages that depict interactions with 3D geometries to introduce external interaction priors. However, they are still vulnerable to a limited semantic space by failing to leverage implied invariant geometries and potential interaction intentions. Normally, humans address complex tasks through multi-step reasoning and respond to diverse situations by leveraging associative and analogical thinking. In light of this, we propose GREAT (GeometRy-intEntion collAboraTive inference) for Open-Vocabulary 3D Object Affordance Grounding, a novel framework that mines the object invariant geometry attributes and performs analogically reason in potential interaction scenarios to form affordance knowledge, fully combining the knowledge with both geometries and visual contents to ground 3D object affordance. Besides, we introduce the Point Image Affordance Dataset v2 (PIADv2), the largest 3D object affordance dataset at present to support the task. Extensive experiments demonstrate the effectiveness and superiority of GREAT. Code and dataset are available at project.