 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network and Spatiotemporal Transformer Attention for 3D Video Object Detection from Point Clouds
Paper and Code
Jul 26, 2022


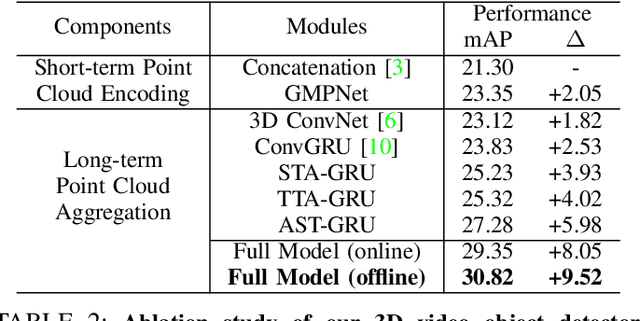
Previous works for LiDAR-based 3D object detection mainly focus on the single-frame paradigm. In this paper, we propose to detect 3D objects by exploiting temporal information in multiple frames, i.e., the point cloud videos. We empirically categorize the temporal information into short-term and long-term patterns. To encode the short-term data, we present a Grid Message Passing Network (GMPNet), which considers each grid (i.e., the grouped points) as a node and constructs a k-NN graph with the neighbor grids. To update features for a grid, GMPNet iteratively collects information from its neighbors, thus mining the motion cues in grids from nearby frames. To further aggregate the long-term frames, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU), which contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module. STA and TTA enhance the vanilla GRU to focus on small objects and better align the moving objects. Our overall framework supports both online and offline video object detection in point clouds. We implement our algorithm based on prevalent anchor-based and anchor-free detectors. The evaluation results on the challenging nuScenes benchmark show the superior performance of our method, achieving the 1st on the leaderboard without any bells and whistles, by the time the paper is submitted.