 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPS: A Policy-driven Sampling Approach for Graph Representation Learning
Paper and Code
Jan 19, 2022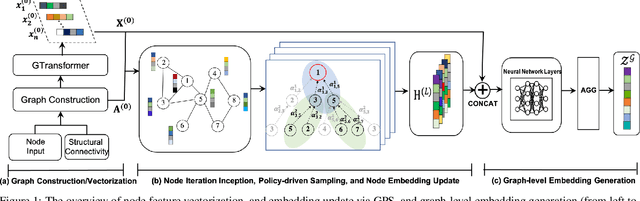
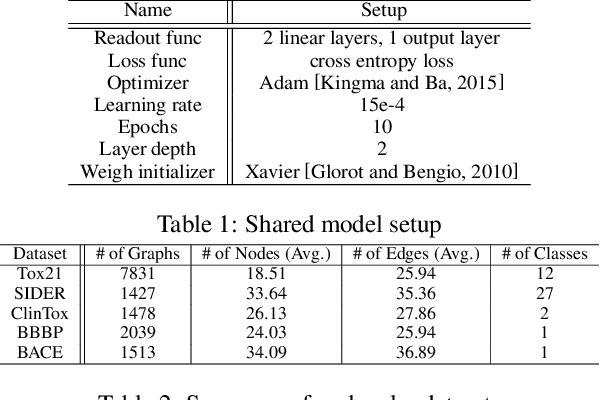
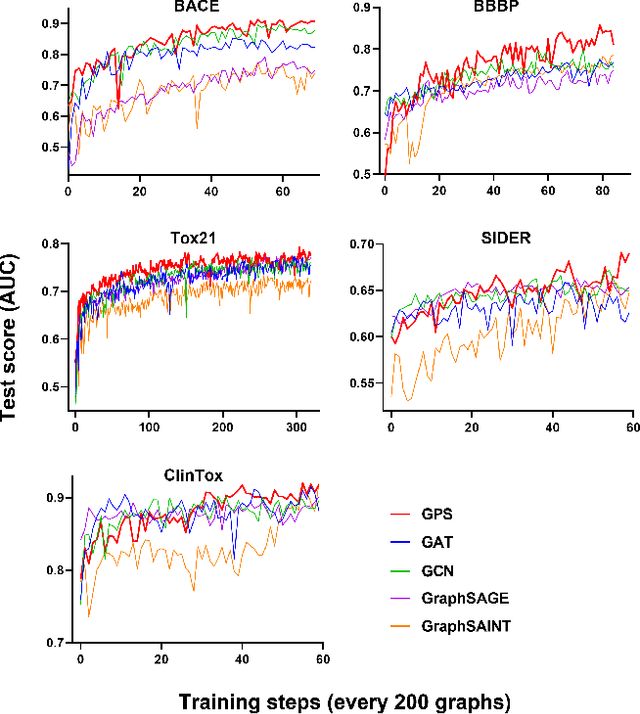

Graph representation learning has drawn increasing attention in recent years, especially for learning the low dimensional embedding at both node and graph level for classification and recommendations tasks. To enable learning the representation on the large-scale graph data in the real world, numerous research has focused on developing different sampling strategies to facilitate the training process. Herein, we propose an adaptive Graph Policy-driven Sampling model (GPS), where the influence of each node in the local neighborhood is realized through the adaptive correlation calculation. Specifically, the selections of the neighbors are guided by an adaptive policy algorithm, contributing directly to the message aggregation, node embedding updating, and graph level readout steps. We then conduct comprehensive experiments against baseline methods on graph classification tasks from various perspectives. Our proposed model outperforms the existing ones by 3%-8% on several vital benchmarks, achieving state-of-the-art performance in real-world datasets.