 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussiGAN: Controllable Image Synthesis with 3D Gaussians from Unposed Silhouettes
Paper and Code
Jun 24, 2021
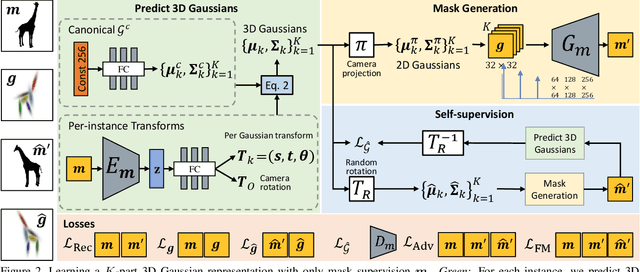
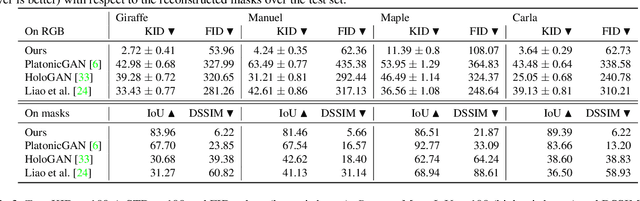

We present an algorithm that learns a coarse 3D representation of objects from unposed multi-view 2D mask supervision, then uses it to generate detailed mask and image texture. In contrast to existing voxel-based methods for unposed object reconstruction, our approach learns to represent the generated shape and pose with a set of self-supervised canonical 3D anisotropic Gaussians via a perspective camera, and a set of per-image transforms. We show that this approach can robustly estimate a 3D space for the camera and object, while recent baselines sometimes struggle to reconstruct coherent 3D spaces in this setting. We show results on synthetic datasets with realistic lighting, and demonstrate object insertion with interactive posing. With our work, we help move towards structured representations that handle more real-world variation in learning-based object reconstruction.