 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget Less, Count Better: A Domain-Incremental Self-Distillation Learning Benchmark for Lifelong Crowd Counting
Paper and Code
May 06, 2022

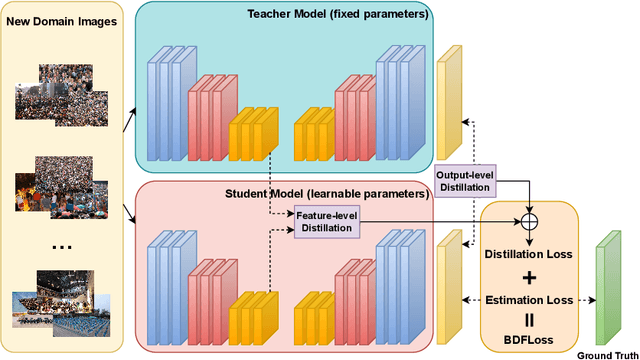
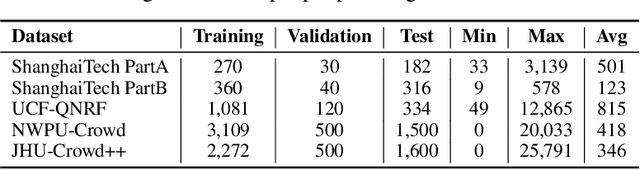
Crowd Counting has important applications in public safety and pandemic control. A robust and practical crowd counting system has to be capable of continuously learning with the new-coming domain data in real-world scenarios instead of fitting one domain only. Off-the-shelf methods have some drawbacks to handle multiple domains. 1) The models will achieve limited performance (even drop dramatically) among old domains after training images from new domains due to the discrepancies of intrinsic data distributions from various domains, which is called catastrophic forgetting. 2) The well-trained model in a specific domain achieves imperfect performance among other unseen domains because of the domain shift. 3) It leads to linearly-increased storage overhead either mixing all the data for training or simply training dozens of separate models for different domains when new ones are available. To overcome these issues, we investigate a new task of crowd counting under the incremental domains training setting, namely, Lifelong Crowd Counting. It aims at alleviating the catastrophic forgetting and improving the generalization ability using a single model updated by the incremental domains. To be more specific, we propose a self-distillation learning framework as a benchmark~(Forget Less, Count Better, FLCB) for lifelong crowd counting, which helps the model sustainably leverage previous meaningful knowledge for better crowd counting to mitigate the forgetting when the new data arrive. Meanwhile, a new quantitative metric, normalized backward transfer~(nBwT), is developed to evaluate the forgetting degree of the model in the lifelong learning process. Extensive experimental results demonstrate the superiority of our proposed benchmark in achieving a low catastrophic forgetting degree and strong generalization ability.