 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow Your Path: a Progressive Method for Knowledge Distillation
Paper and Code
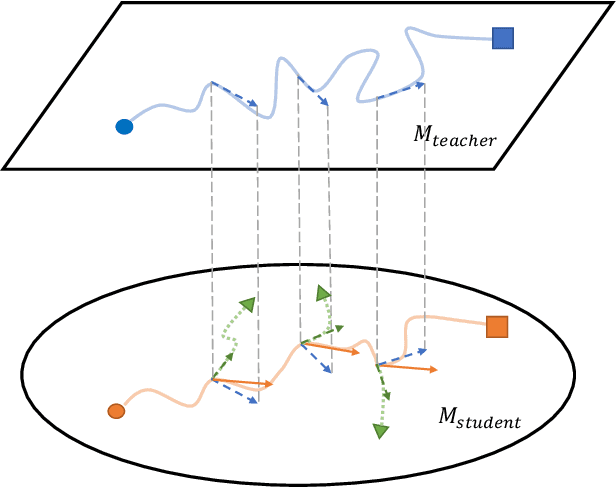


Deep neural networks often have a huge number of parameters, which posts challenges in deployment in application scenarios with limited memory and computation capacity. Knowledge distillation is one approach to derive compact models from bigger ones. However, it has been observed that a converged heavy teacher model is strongly constrained for learning a compact student network and could make the optimization subject to poor local optima. In this paper, we propose ProKT, a new model-agnostic method by projecting the supervision signals of a teacher model into the student's parameter space. Such projection is implemented by decomposing the training objective into local intermediate targets with an approximate mirror descent technique. The proposed method could be less sensitive with the quirks during optimization which could result in a better local optimum. Experiments on both image and text datasets show that our proposed ProKT consistently achieves superior performance compared to other existing knowledge distillation methods.