 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Car Detection for Visual Census Estimation
Paper and Code
Sep 07, 2017
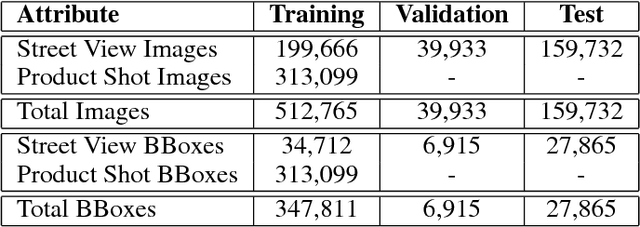
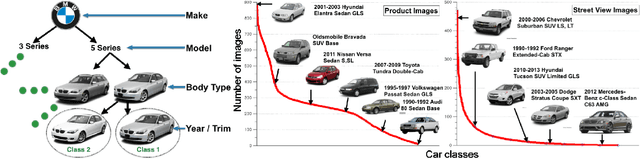
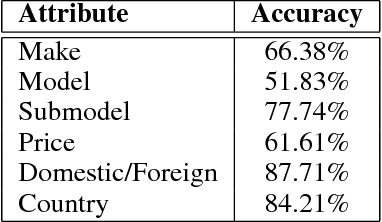
Targeted socioeconomic policies require an accurate understanding of a country's demographic makeup. To that end, the United States spends more than 1 billion dollars a year gathering census data such as race, gender, education, occupation and unemployment rates. Compared to the traditional method of collecting surveys across many years which is costly and labor intensive, data-driven, machine learning driven approaches are cheaper and faster--with the potential ability to detect trends in close to real time. In this work, we leverage the ubiquity of Google Street View images and develop a computer vision pipeline to predict income, per capita carbon emission, crime rates and other city attributes from a single source of publicly available visual data. We first detect cars in 50 million images across 200 of the largest US cities and train a model to predict demographic attributes using the detected cars. To facilitate our work, we have collected the largest and most challenging fine-grained dataset reported to date consisting of over 2600 classes of cars comprised of images from Google Street View and other web sources, classified by car experts to account for even the most subtle of visual differences. We use this data to construct the largest scale fine-grained detection system reported to date. Our prediction results correlate well with ground truth income data (r=0.82), Massachusetts department of vehicle registration, and sources investigating crime rates, income segregation, per capita carbon emission, and other market research. Finally, we learn interesting relationships between cars and neighborhoods allowing us to perform the first large scale sociological analysis of cities using computer vision techniques.