 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Unsupervised Representation Learning
Paper and Code
Oct 18, 2020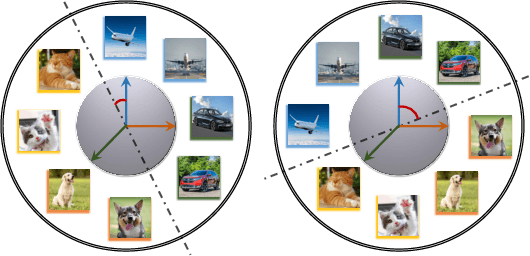
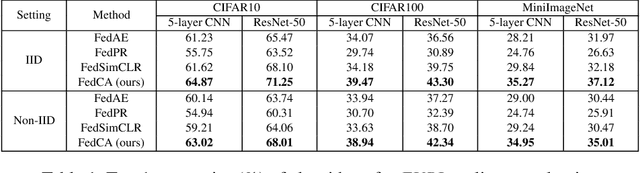
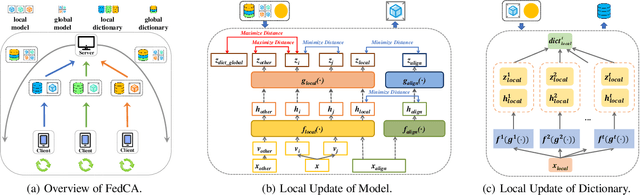
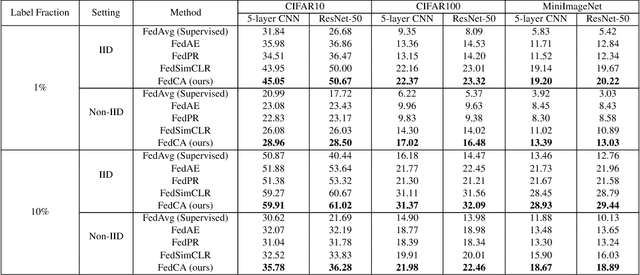
To leverage enormous unlabeled data on distributed edge devices, we formulate a new problem in federated learning called Federated Unsupervised Representation Learning (FURL) to learn a common representation model without supervision while preserving data privacy. FURL poses two new challenges: (1) data distribution shift (Non-IID distribution) among clients would make local models focus on different categories, leading to the inconsistency of representation spaces. (2) without the unified information among clients in FURL, the representations across clients would be misaligned. To address these challenges, we propose Federated Constrastive Averaging with dictionary and alignment (FedCA) algorithm. FedCA is composed of two key modules: (1) dictionary module to aggregate the representations of samples from each client and share with all clients for consistency of representation space and (2) alignment module to align the representation of each client on a base model trained on a public data. We adopt the contrastive loss for local model training. Through extensive experiments with three evaluation protocols in IID and Non-IID settings, we demonstrate that FedCA outperforms all baselines with significant margins.