 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Neural Bandit
Paper and Code
May 28, 2022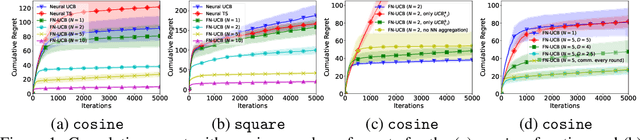
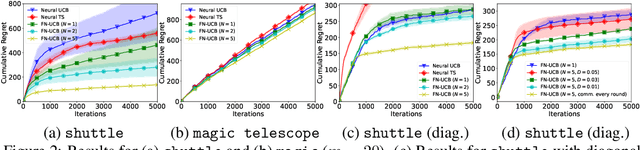
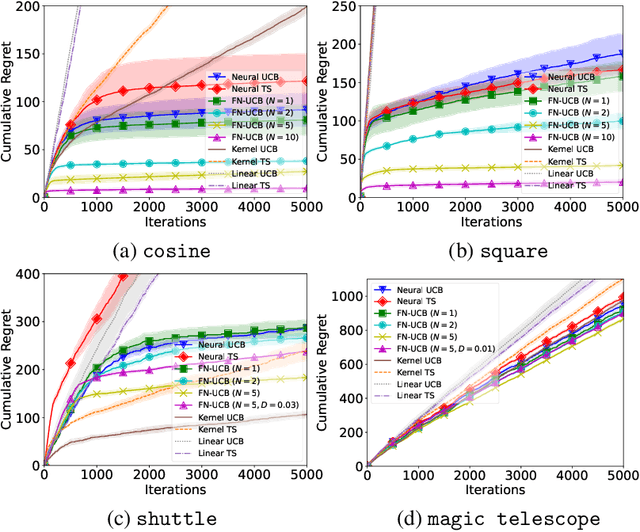
Recent works on neural contextual bandit have achieved compelling performances thanks to their ability to leverage the strong representation power of neural networks (NNs) for reward prediction. Many applications of contextual bandit involve multiple agents who collaborate without sharing raw observations, giving rise to the setting of federated contextual bandit. Existing works on federated contextual bandit rely on linear or kernelized bandit, which may fall short when modeling complicated real-world reward functions. In this regard, we introduce the federated neural-upper confidence bound (FN-UCB) algorithm. To better exploit the federated setting, we adopt a weighted combination of two UCBs: $\text{UCB}^{a}$ allows every agent to additionally use the observations from the other agents to accelerate exploration (without sharing raw observations); $\text{UCB}^{b}$ uses an NN with aggregated parameters for reward prediction in a similar way as federated averaging for supervised learning. Notably, the weight between the two UCBs required by our theoretical analysis is amenable to an interesting interpretation, which emphasizes $\text{UCB}^{a}$ initially for accelerated exploration and relies more on $\text{UCB}^{b}$ later after enough observations have been collected to train the NNs for accurate reward prediction (i.e., reliable exploitation). We prove sub-linear upper bounds on both the cumulative regret and the number of communication rounds of FN-UCB, and use empirical experiments to demonstrate its competitive performances.