 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASTER Recurrent Networks for Video Classification
Paper and Code
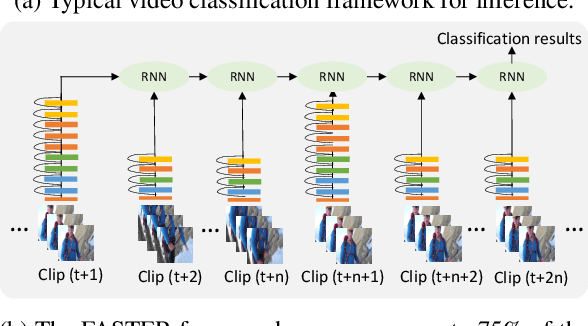
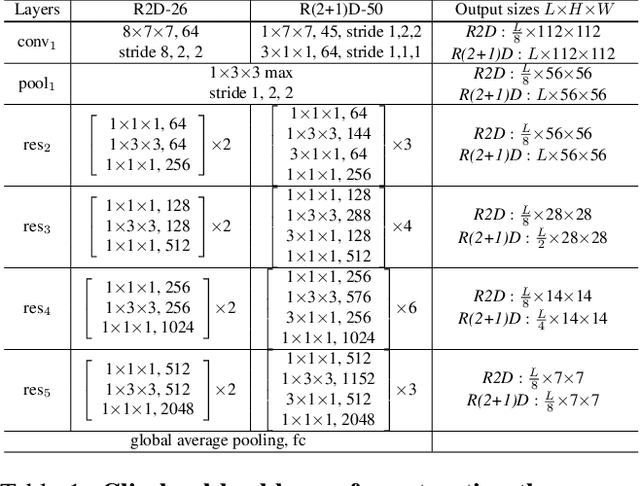
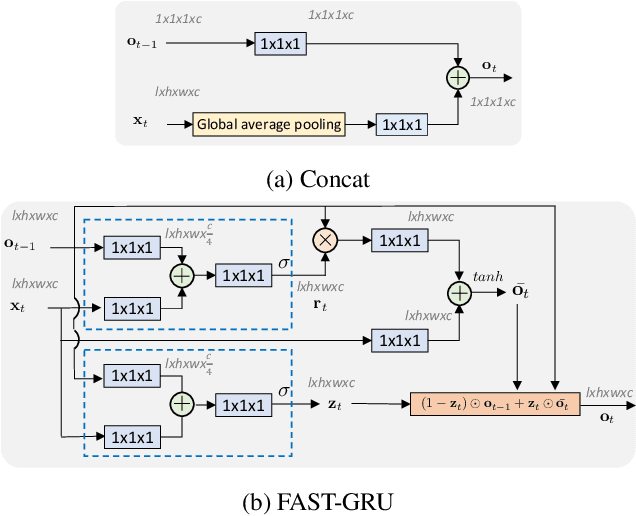
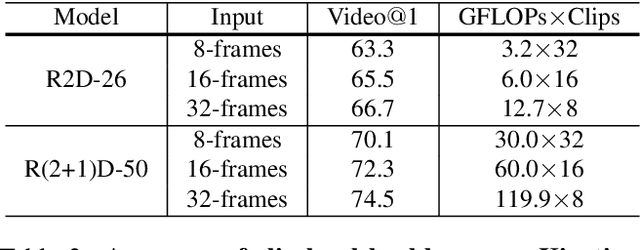
Video classification methods often divide the video into short clips, do inference on these clips independently, and then aggregate these predictions to generate the final classification result. Treating these highly-correlated clips as independent both ignores the temporal structure of the signal and carries a large computational cost: the model must process each clip from scratch. To reduce this cost, recent efforts have focused on designing more efficient clip-level network architectures. Less attention, however, has been paid to the overall framework, including how to benefit from correlations between neighboring clips and improving the aggregation strategy itself. In this paper we leverage the correlation between adjacent video clips to address the problem of computational cost efficiency in video classification at the aggregation stage. More specifically, given a clip feature representation, the problem of computing next clip's representation becomes much easier. We propose a novel recurrent architecture called FASTER for video-level classification, that combines high quality, expensive representations of clips, that capture the action in detail, and lightweight representations, which capture scene changes in the video and avoid redundant computation. We also propose a novel processing unit to learn integration of clip-level representations, as well as their temporal structure. We call this unit FAST-GRU, as it is based on the Gated Recurrent Unit (GRU). The proposed framework achieves significantly better FLOPs vs. accuracy trade-off at inference time. Compared to existing approaches, our proposed framework reduces the FLOPs by more than 10x while maintaining similar accuracy across popular datasets, such as Kinetics, UCF101 and HMDB51.