 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Generating A Large Number of Gumbel-Max Variables
Paper and Code
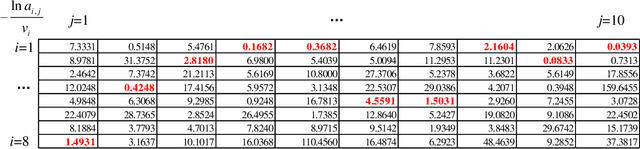
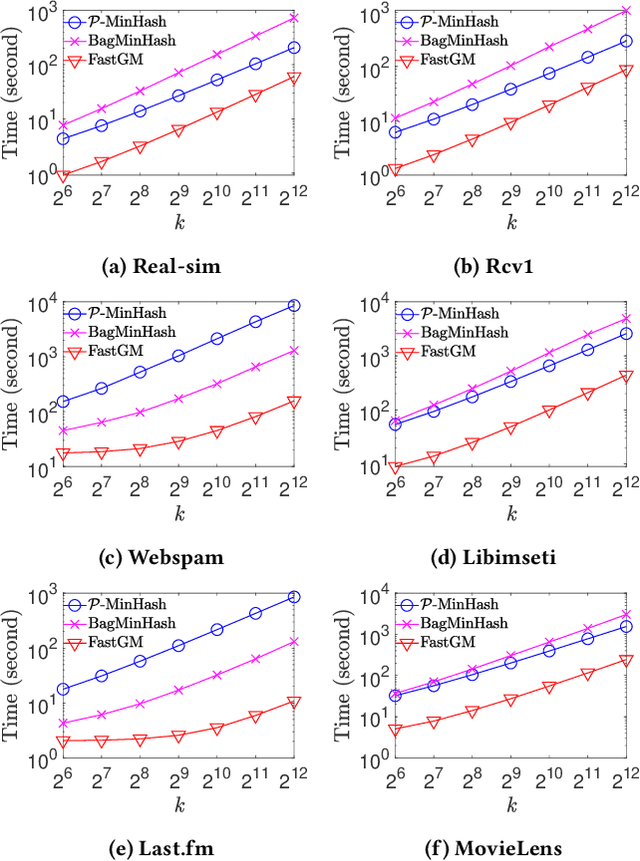
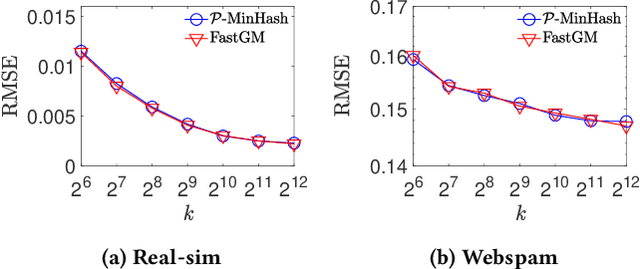
The well-known Gumbel-Max Trick for sampling elements from a categorical distribution (or more generally a nonnegative vector) and its variants have been widely used in areas such as machine learning and information retrieval. To sample a random element $i$ (or a Gumbel-Max variable $i$) in proportion to its positive weight $v_i$, the Gumbel-Max Trick first computes a Gumbel random variable $g_i$ for each positive weight element $i$, and then samples the element $i$ with the largest value of $g_i+\ln v_i$. Recently, applications including similarity estimation and graph embedding require to generate $k$ independent Gumbel-Max variables from high dimensional vectors. However, it is computationally expensive for a large $k$ (e.g., hundreds or even thousands) when using the traditional Gumbel-Max Trick. To solve this problem, we propose a novel algorithm, \emph{FastGM}, that reduces the time complexity from $O(kn^+)$ to $O(k \ln k + n^+)$, where $n^+$ is the number of positive elements in the vector of interest. Instead of computing $k$ independent Gumbel random variables directly, we find that there exists a technique to generate these variables in descending order. Using this technique, our method FastGM computes variables $g_i+\ln v_i$ for all positive elements $i$ in descending order. As a result, FastGM significantly reduces the computation time because we can stop the procedure of Gumbel random variables computing for many elements especially for those with small weights. Experiments on a variety of real-world datasets show that FastGM is orders of magnitude faster than state-of-the-art methods without sacrificing accuracy and incurring additional expenses.