 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorised Representation Learning in Cardiac Image Analysis
Paper and Code
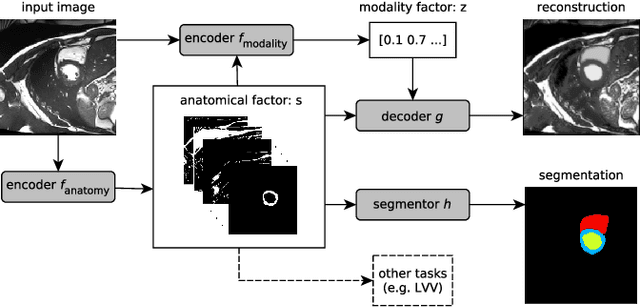
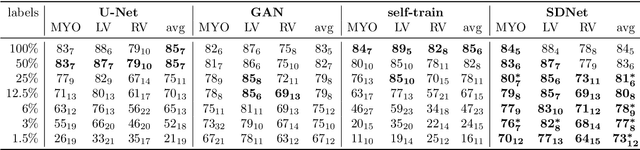
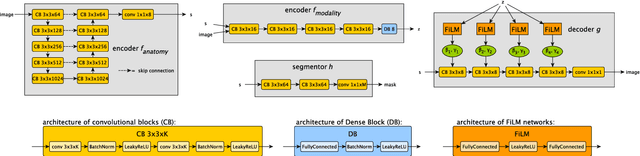
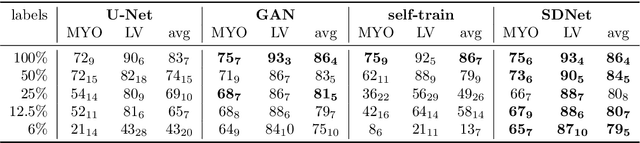
Typically, a medical image offers spatial information on the anatomy (and pathology) modulated by imaging specific characteristics. Many imaging modalities including Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) can be interpreted in this way. We can venture further and consider that a medical image naturally factors into some spatial factors depicting anatomy and factors that denote the imaging characteristics. Here, we explicitly learn this decomposed (factorised) representation of imaging data, focusing in particular on cardiac images. We propose Spatial Decomposition Network (SDNet), which factorises 2D medical images into spatial anatomical factors and non-spatial imaging factors. We demonstrate that this high-level representation is ideally suited for several medical image analysis tasks, such as semi-supervised segmentation, multi-task segmentation and regression, and image-to-image synthesis. Specifically, we show that our model can match the performance of fully supervised segmentation models, using only a fraction of the labelled images. Critically, we show that our factorised representation also benefits from supervision obtained either when we use auxiliary tasks to train the model in a multi-task setting (e.g. regressing to known cardiac indices), or when aggregating multimodal data from different sources (e.g. pooling together MRI and CT data). To explore the properties of the learned factorisation, we perform latent-space arithmetic and show that we can synthesise CT from MR and vice versa, by swapping the modality factors. We also demonstrate that the factor holding image specific information can be used to predict the input modality with high accuracy.