 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Rich Syntactic Information for Semantic Parsing with Graph-to-Sequence Model
Paper and Code
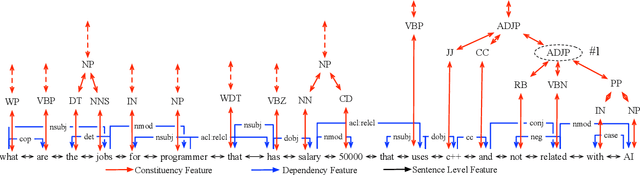
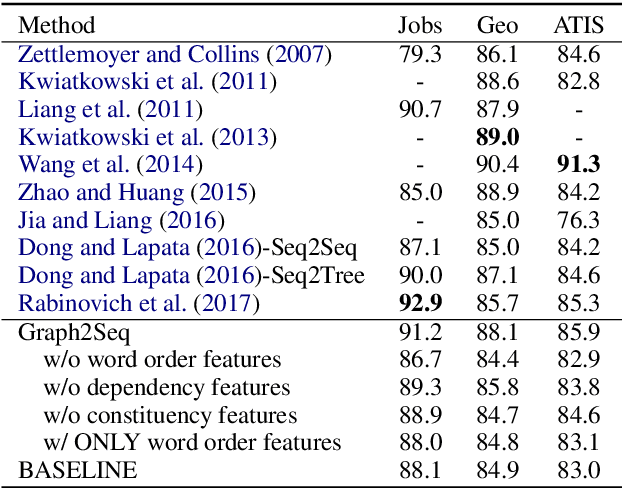

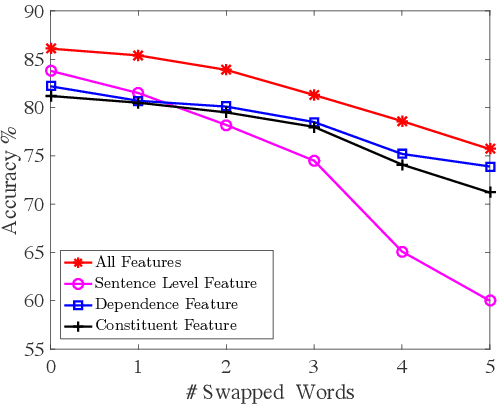
Existing neural semantic parsers mainly utilize a sequence encoder, i.e., a sequential LSTM, to extract word order features while neglecting other valuable syntactic information such as dependency graph or constituent trees. In this paper, we first propose to use the \textit{syntactic graph} to represent three types of syntactic information, i.e., word order, dependency and constituency features. We further employ a graph-to-sequence model to encode the syntactic graph and decode a logical form. Experimental results on benchmark datasets show that our model is comparable to the state-of-the-art on Jobs640, ATIS and Geo880. Experimental results on adversarial examples demonstrate the robustness of the model is also improved by encoding more syntactic information.