 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating natural language processing models with generalization metrics that do not need access to any training or testing data
Paper and Code
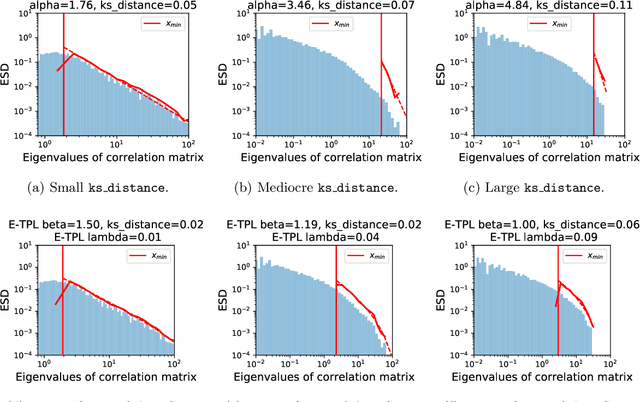
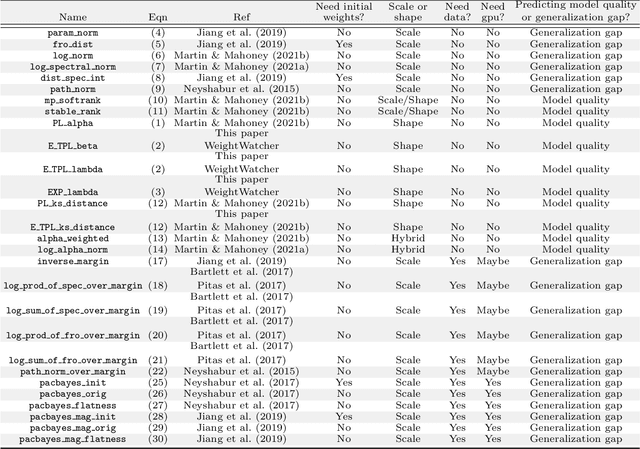
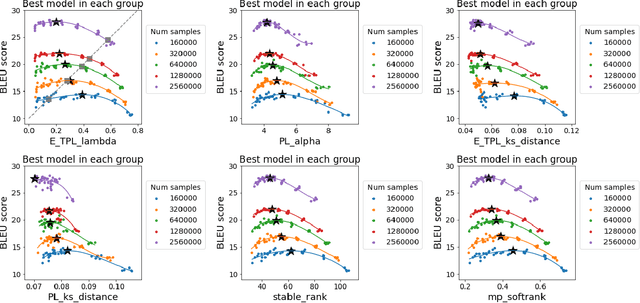

The search for effective and robust generalization metrics has been the focus of recent theoretical and empirical work. In this paper, we discuss the performance of natural language processing (NLP) models, and we evaluate various existing and novel generalization metrics. Compared to prior studies, we (i) focus on NLP instead of computer vision (CV), (ii) focus on generalization metrics that predict test error instead of the generalization gap, (iii) focus on generalization metrics that do not need the access to data, and (iv) focus on the heavy-tail (HT) phenomenon that has received comparatively less attention in the study of deep neural networks (NNs). We extend recent HT-based work which focuses on power law (PL) distributions, and we study exponential (EXP) and exponentially truncated power law (E-TPL) fitting to the empirical spectral densities (ESDs) of weight matrices. Our detailed empirical studies show that (i) \emph{shape metrics}, or the metrics obtained from fitting the shape of the ESDs, perform uniformly better at predicting generalization performance than \emph{scale metrics} commonly studied in the literature, as measured by the \emph{average} rank correlations with the generalization performance for all of our experiments; (ii) among forty generalization metrics studied in our paper, the \RANDDISTANCE metric, a new shape metric invented in this paper that measures the distance between empirical eigenvalues of weight matrices and those of randomly initialized weight matrices, achieves the highest worst-case rank correlation with generalization performance under a variety of training settings; and (iii) among the three HT distributions considered in our paper, the E-TPL fitting of ESDs performs the most robustly.