 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Extrapolation Performance of Dense Retrieval
Paper and Code

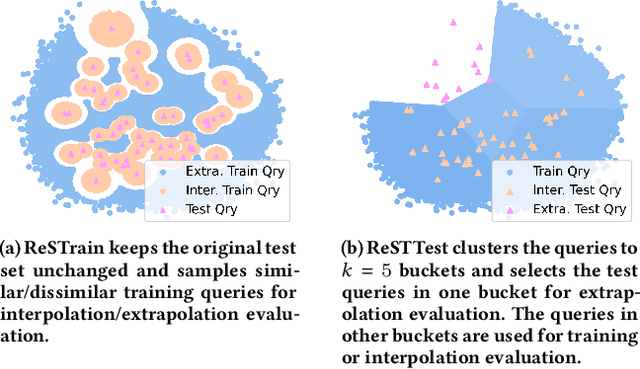

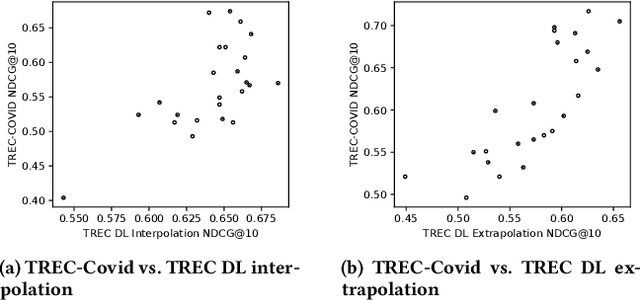
A retrieval model should not only interpolate the training data but also extrapolate well to the queries that are rather different from the training data. While dense retrieval (DR) models have been demonstrated to achieve better retrieval performance than the traditional term-based retrieval models, we still know little about whether they can extrapolate. To shed light on the research question, we investigate how DR models perform in both the interpolation and extrapolation regimes. We first investigate the distribution of training and test data on popular retrieval benchmarks and identify a considerable overlap in query entities, query intent, and relevance labels. This finding implies that the performance on these test sets is biased towards interpolation and cannot accurately reflect the extrapolation capacity. Therefore, to evaluate the extrapolation performance of DR models, we propose two resampling strategies for existing retrieval benchmarks and comprehensively investigate how DR models perform. Results show that DR models may interpolate as well as complex interaction-based models (e.g., BERT and ColBERT) but extrapolate substantially worse. Among various DR training strategies, text-encoding pretraining and target-domain pretraining are particularly effective for improving the extrapolation capacity. Finally, we compare the extrapolation capacity with domain transfer ability. Despite its simplicity and ease of use, the extrapolation performance can reflect the domain transfer ability in some domains of the BEIR dataset, further highlighting the feasibility of our approaches in evaluating the generalizability of DR models.