 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Efficient Training of SNN using Local Zeroth Order Method
Paper and Code
Feb 05, 2023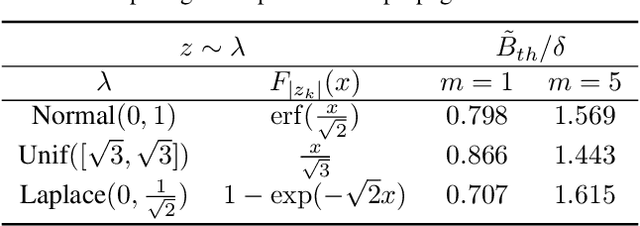


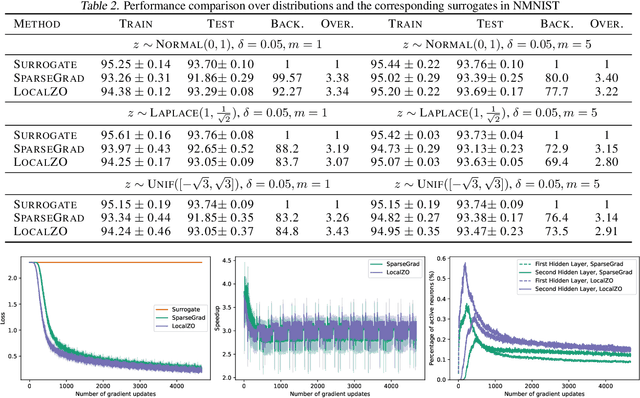
Spiking neural networks are becoming increasingly popular for their low energy requirement in real-world tasks with accuracy comparable to the traditional ANNs. SNN training algorithms face the loss of gradient information and non-differentiability due to the Heaviside function in minimizing the model loss over model parameters. To circumvent the problem surrogate method uses a differentiable approximation of the Heaviside in the backward pass, while the forward pass uses the Heaviside as the spiking function. We propose to use the zeroth order technique at the neuron level to resolve this dichotomy and use it within the automatic differentiation tool. As a result, we establish a theoretical connection between the proposed local zeroth-order technique and the existing surrogate methods and vice-versa. The proposed method naturally lends itself to energy-efficient training of SNNs on GPUs. Experimental results with neuromorphic datasets show that such implementation requires less than 1 percent neurons to be active in the backward pass, resulting in a 100x speed-up in the backward computation time. Our method offers better generalization compared to the state-of-the-art energy-efficient technique while maintaining similar efficiency.