 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Concepts in Graph Neural Networks
Paper and Code
Aug 07, 2022

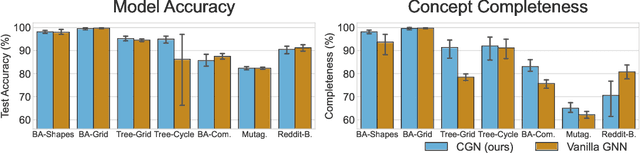

The opaque reasoning of Graph Neural Networks induces a lack of human trust. Existing graph network explainers attempt to address this issue by providing post-hoc explanations, however, they fail to make the model itself more interpretable. To fill this gap, we introduce the Concept Encoder Module, the first differentiable concept-discovery approach for graph networks. The proposed approach makes graph networks explainable by design by first discovering graph concepts and then using these to solve the task. Our results demonstrate that this approach allows graph networks to: (i) attain model accuracy comparable with their equivalent vanilla versions, (ii) discover meaningful concepts that achieve high concept completeness and purity scores, (iii) provide high-quality concept-based logic explanations for their prediction, and (iv) support effective interventions at test time: these can increase human trust as well as significantly improve model performance.