 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Knowledge for Document Summarization: A Survey
Paper and Code
Apr 24, 2022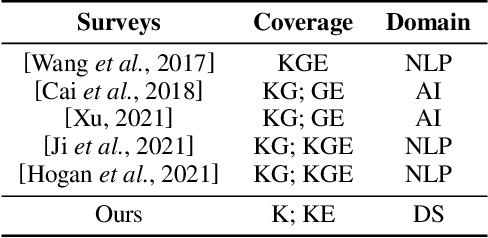
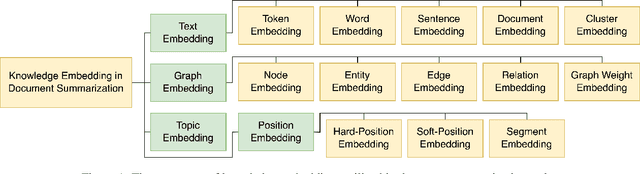
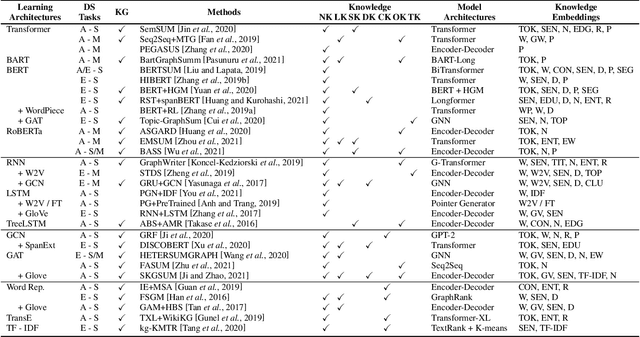
Knowledge-aware methods have boosted a range of Natural Language Processing applications over the last decades. With the gathered momentum, knowledge recently has been pumped into enormous attention in document summarization research. Previous works proved that knowledge-embedded document summarizers excel at generating superior digests, especially in terms of informativeness, coherence, and fact consistency. This paper pursues to present the first systematic survey for the state-of-the-art methodologies that embed knowledge into document summarizers. Particularly, we propose novel taxonomies to recapitulate knowledge and knowledge embeddings under the document summarization view. We further explore how embeddings are generated in learning architectures of document summarization models, especially in deep learning models. At last, we discuss the challenges of this topic and future directions.