 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently sampling functions from Gaussian process posteriors
Paper and Code
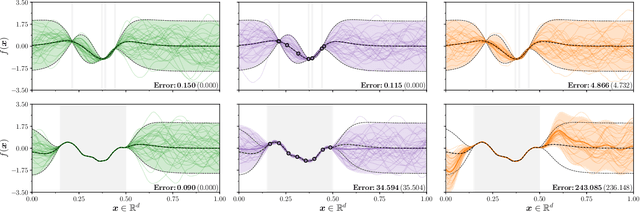
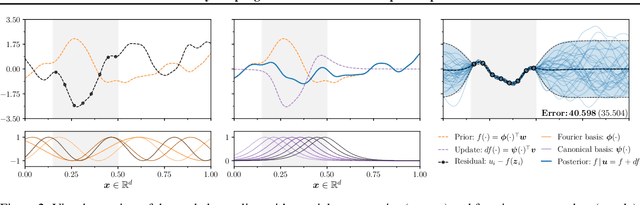
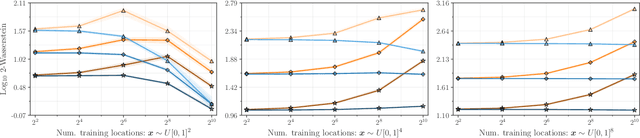
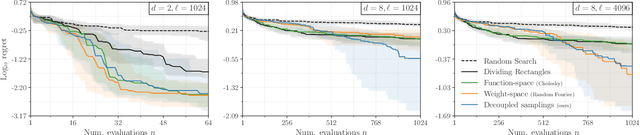
Gaussian processes are the gold standard for many real-world modeling problems, especially in cases where a model's success hinges upon its ability to faithfully represent predictive uncertainty. These problems typically exist as parts of larger frameworks, where quantities of interest are ultimately defined by integrating over posterior distributions. However, these algorithms' inner workings rarely allow for closed-form integration, giving rise to a need for Monte Carlo methods. Despite substantial progress in scaling up Gaussian processes to large training sets, methods for accurately generating draws from their posterior distributions still scale cubically in the number of test locations. We identify a decomposition of Gaussian processes that naturally lends itself to scalable sampling by enabling us to efficiently generate functions that accurately represent their posteriors. Building off of this factorization, we propose decoupled sampling, an easy-to-use and general-purpose approach for fast posterior sampling. Decoupled sampling works as a drop-in strategy that seamlessly pairs with sparse approximations to Gaussian processes to afford scalability both during training and at test time. In a series of experiments designed to test competing sampling schemes' statistical behaviors and practical ramifications, we empirically show that functions drawn using decoupled sampling faithfully represent Gaussian process posteriors at a fraction of the usual cost.