 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Lingual Transfer for Chinese Stable Diffusion with Images as Pivots
Paper and Code



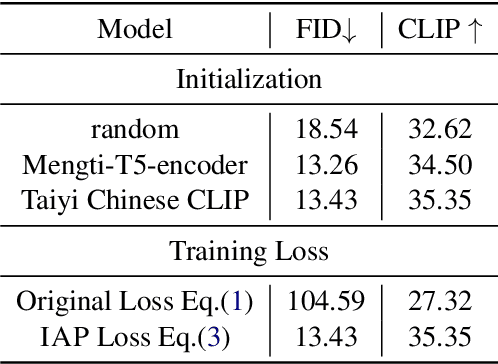
Diffusion models have made impressive progress in text-to-image synthesis. However, training such large-scale models (e.g. Stable Diffusion), from scratch requires high computational costs and massive high-quality text-image pairs, which becomes unaffordable in other languages. To handle this challenge, we propose IAP, a simple but effective method to transfer English Stable Diffusion into Chinese. IAP optimizes only a separate Chinese text encoder with all other parameters fixed to align Chinese semantics space to the English one in CLIP. To achieve this, we innovatively treat images as pivots and minimize the distance of attentive features produced from cross-attention between images and each language respectively. In this way, IAP establishes connections of Chinese, English and visual semantics in CLIP's embedding space efficiently, advancing the quality of the generated image with direct Chinese prompts. Experimental results show that our method outperforms several strong Chinese diffusion models with only 5%~10% training data.