 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-Net++: Dynamic Weight Slicing for Efficient Inference in CNNs and Transformers
Paper and Code
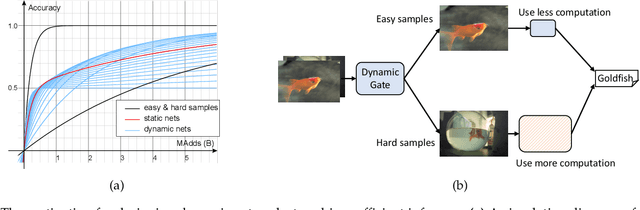
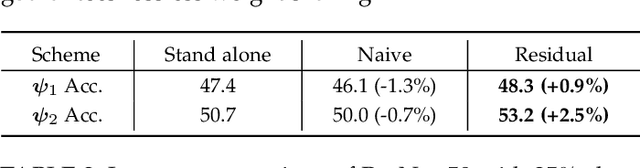

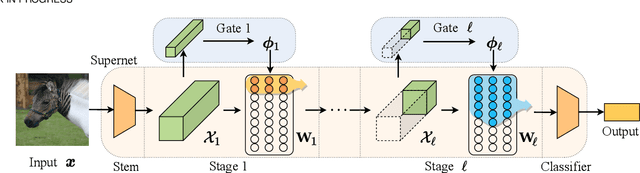
Dynamic networks have shown their promising capability in reducing theoretical computation complexity by adapting their architectures to the input during inference. However, their practical runtime usually lags behind the theoretical acceleration due to inefficient sparsity. Here, we explore a hardware-efficient dynamic inference regime, named dynamic weight slicing, which adaptively slice a part of network parameters for inputs with diverse difficulty levels, while keeping parameters stored statically and contiguously in hardware to prevent the extra burden of sparse computation. Based on this scheme, we present dynamic slimmable network (DS-Net) and dynamic slice-able network (DS-Net++) by input-dependently adjusting filter numbers of CNNs and multiple dimensions in both CNNs and transformers, respectively. To ensure sub-network generality and routing fairness, we propose a disentangled two-stage optimization scheme with training techniques such as in-place bootstrapping (IB), multi-view consistency (MvCo) and sandwich gate sparsification (SGS) to train supernet and gate separately. Extensive experiments on 4 datasets and 3 different network architectures demonstrate our method consistently outperforms state-of-the-art static and dynamic model compression methods by a large margin (up to 6.6%). Typically, DS-Net++ achieves 2-4x computation reduction and 1.62x real-world acceleration over MobileNet, ResNet-50 and Vision Transformer, with minimal accuracy drops (0.1-0.3%) on ImageNet. Code release: https://github.com/changlin31/DS-Net