 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDnS: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval
Paper and Code
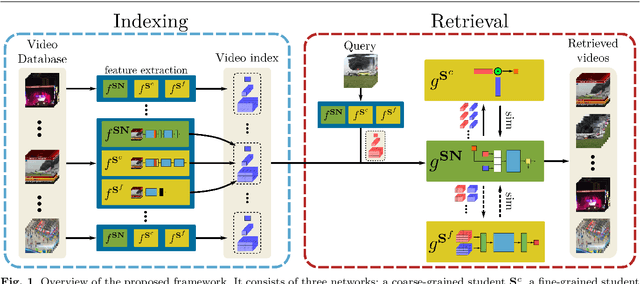

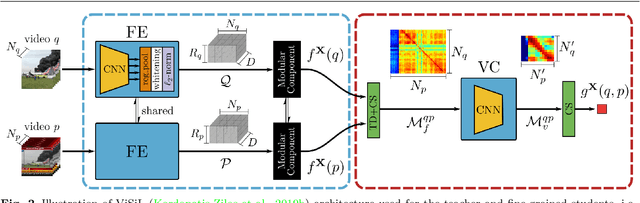

In this paper, we address the problem of high performance and computationally efficient content-based video retrieval in large-scale datasets. Current methods typically propose either: (i) fine-grained approaches employing spatio-temporal representations and similarity calculations, achieving high performance at a high computational cost or (ii) coarse-grained approaches representing/indexing videos as global vectors, where the spatio-temporal structure is lost, providing low performance but also having low computational cost. In this work, we propose a Knowledge Distillation framework, which we call Distill-and-Select (DnS), that starting from a well-performing fine-grained Teacher Network learns: a) Student Networks at different retrieval performance and computational efficiency trade-offs and b) a Selection Network that at test time rapidly directs samples to the appropriate student to maintain both high retrieval performance and high computational efficiency. We train several students with different architectures and arrive at different trade-offs of performance and efficiency, i.e., speed and storage requirements, including fine-grained students that store index videos using binary representations. Importantly, the proposed scheme allows Knowledge Distillation in large, unlabelled datasets -- this leads to good students. We evaluate DnS on five public datasets on three different video retrieval tasks and demonstrate a) that our students achieve state-of-the-art performance in several cases and b) that our DnS framework provides an excellent trade-off between retrieval performance, computational speed, and storage space. In specific configurations, our method achieves similar mAP with the teacher but is 20 times faster and requires 240 times less storage space. Our collected dataset and implementation are publicly available: https://github.com/mever-team/distill-and-select.