Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Exploration via Conjugate Policies for Policy Gradient Methods
Paper and Code
Feb 10, 2019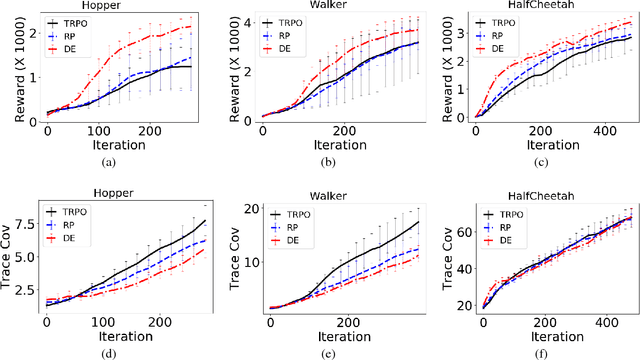
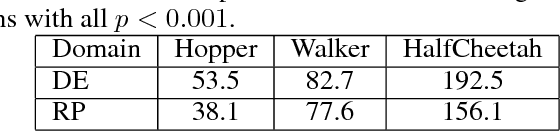
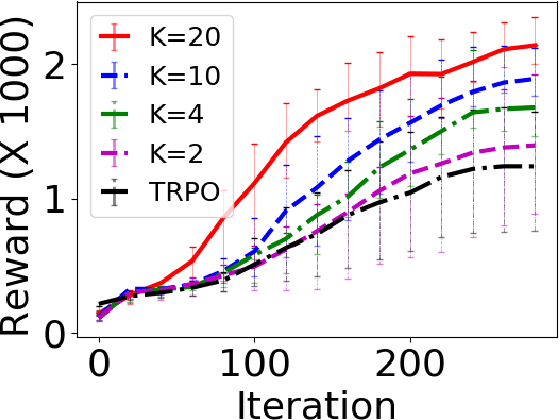
We address the challenge of effective exploration while maintaining good performance in policy gradient methods. As a solution, we propose diverse exploration (DE) via conjugate policies. DE learns and deploys a set of conjugate policies which can be conveniently generated as a byproduct of conjugate gradient descent. We provide both theoretical and empirical results showing the effectiveness of DE at achieving exploration, improving policy performance, and the advantage of DE over exploration by random policy perturbations.
* AAAI 2019
View paper on