 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Soft Actor Critic for Risk Sensitive Learning
Paper and Code

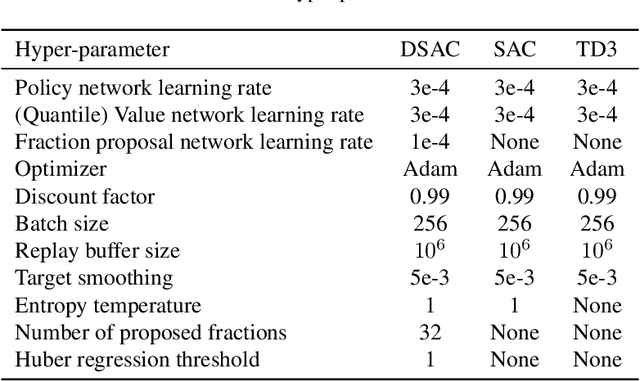

Most of reinforcement learning (RL) algorithms aim at maximizing the expectation of accumulated discounted returns. Since the accumulated discounted return is a random variable, its distribution includes more information than its expectation. Meanwhile, entropy of policy indicates its diversity and it can help improve the exploration capability of algorithms. In this paper, we present a new RL algorithm named Distributional Soft Actor Critic (DSAC), combining distributional RL and maximum entropy RL together. Taking the randomness both in action and discounted return into consideration, DSAC over performs the state-of-the-art baselines with more stability in several continuous control benchmarks. Moreover, distributional information of returns can also be used to measure metrics other than expectation, such as risk-related metrics. With a fully parameterized quantile function, DSAC is easily adopted to optimize policy under different risk preferences. Our experiments demonstrate that with distribution modeling in RL the agent performs better both for risk-averse and risk-seeking control tasks.