 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Redundancy for Multi-Task Pruning
Paper and Code
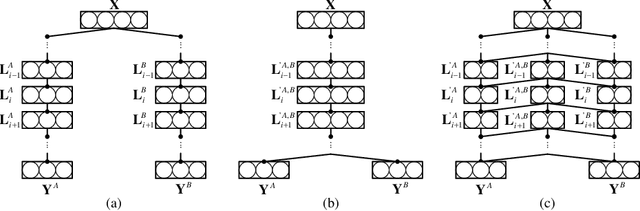
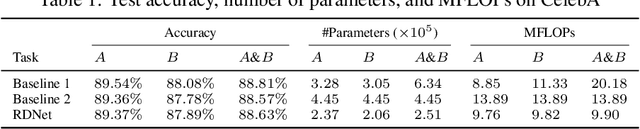
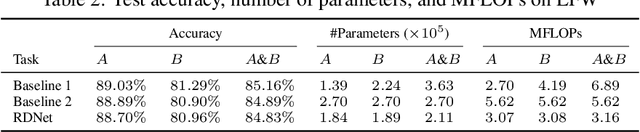
Can prior network pruning strategies eliminate redundancy in multiple correlated pre-trained deep neural networks? It seems a positive answer if multiple networks are first combined and then pruned. However, we argue that an arbitrarily combined network may lead to sub-optimal pruning performance because their intra- and inter-redundancy may not be minimised at the same time while retaining the inference accuracy in each task. In this paper, we define and analyse the redundancy in multi-task networks from an information theoretic perspective, and identify challenges for existing pruning methods to function effectively for multi-task pruning. We propose Redundancy-Disentangled Networks (RDNets), which decouples intra- and inter-redundancy such that all redundancy can be suppressed via previous network pruning schemes. A pruned RDNet also ensures minimal computation in any subset of tasks, a desirable feature for selective task execution. Moreover, a heuristic is devised to construct an RDNet from multiple pre-trained networks. Experiments on CelebA show that the same pruning method on an RDNet achieves at least 1:8x lower memory usage and 1:4x lower computation cost than on a multi-task network constructed by the state-of-the-art network merging scheme.