 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
Paper and Code
Mar 29, 2022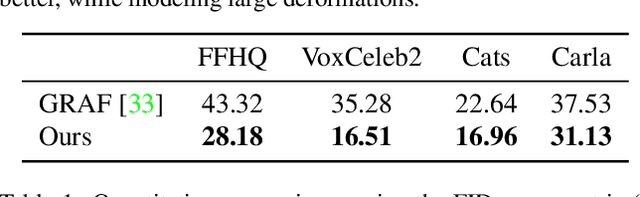
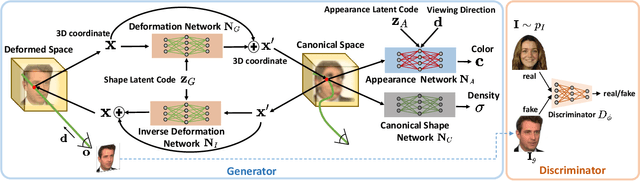


Learning 3D generative models from a dataset of monocular images enables self-supervised 3D reasoning and controllable synthesis. State-of-the-art 3D generative models are GANs which use neural 3D volumetric representations for synthesis. Images are synthesized by rendering the volumes from a given camera. These models can disentangle the 3D scene from the camera viewpoint in any generated image. However, most models do not disentangle other factors of image formation, such as geometry and appearance. In this paper, we design a 3D GAN which can learn a disentangled model of objects, just from monocular observations. Our model can disentangle the geometry and appearance variations in the scene, i.e., we can independently sample from the geometry and appearance spaces of the generative model. This is achieved using a novel non-rigid deformable scene formulation. A 3D volume which represents an object instance is computed as a non-rigidly deformed canonical 3D volume. Our method learns the canonical volume, as well as its deformations, jointly during training. This formulation also helps us improve the disentanglement between the 3D scene and the camera viewpoints using a novel pose regularization loss defined on the 3D deformation field. In addition, we further model the inverse deformations, enabling the computation of dense correspondences between images generated by our model. Finally, we design an approach to embed real images into the latent space of our disentangled generative model, enabling editing of real images.