 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Diverse Multi-Agent Strategic Behavior via Reward Randomization
Paper and Code
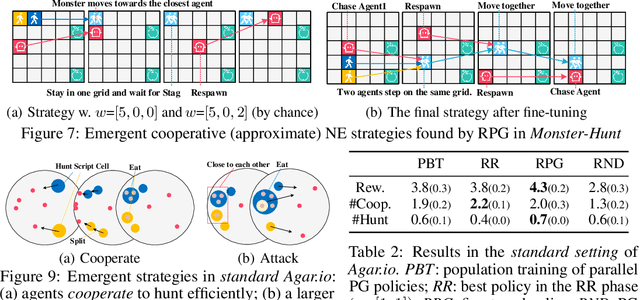
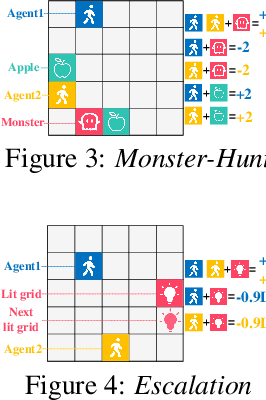
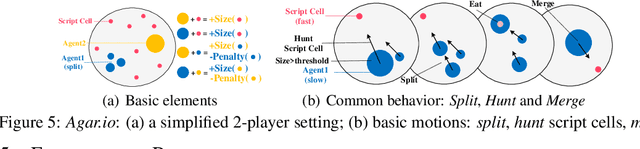
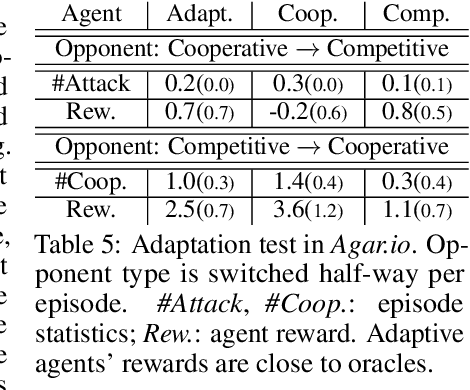
We propose a simple, general and effective technique, Reward Randomization for discovering diverse strategic policies in complex multi-agent games. Combining reward randomization and policy gradient, we derive a new algorithm, Reward-Randomized Policy Gradient (RPG). RPG is able to discover multiple distinctive human-interpretable strategies in challenging temporal trust dilemmas, including grid-world games and a real-world game Agar.io, where multiple equilibria exist but standard multi-agent policy gradient algorithms always converge to a fixed one with a sub-optimal payoff for every player even using state-of-the-art exploration techniques. Furthermore, with the set of diverse strategies from RPG, we can (1) achieve higher payoffs by fine-tuning the best policy from the set; and (2) obtain an adaptive agent by using this set of strategies as its training opponents. The source code and example videos can be found in our website: https://sites.google.com/view/staghuntrpg.