 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirty Pixels: Optimizing Image Classification Architectures for Raw Sensor Data
Paper and Code

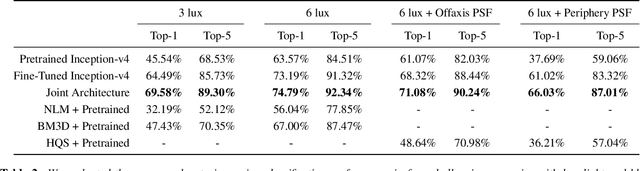

Real-world sensors suffer from noise, blur, and other imperfections that make high-level computer vision tasks like scene segmentation, tracking, and scene understanding difficult. Making high-level computer vision networks robust is imperative for real-world applications like autonomous driving, robotics, and surveillance. We propose a novel end-to-end differentiable architecture for joint denoising, deblurring, and classification that makes classification robust to realistic noise and blur. The proposed architecture dramatically improves the accuracy of a classification network in low light and other challenging conditions, outperforming alternative approaches such as retraining the network on noisy and blurry images and preprocessing raw sensor inputs with conventional denoising and deblurring algorithms. The architecture learns denoising and deblurring pipelines optimized for classification whose outputs differ markedly from those of state-of-the-art denoising and deblurring methods, preserving fine detail at the cost of more noise and artifacts. Our results suggest that the best low-level image processing for computer vision is different from existing algorithms designed to produce visually pleasing images. The principles used to design the proposed architecture easily extend to other high-level computer vision tasks and image formation models, providing a general framework for integrating low-level and high-level image processing.