 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional ASR: A New Paradigm for E2E Multi-Speaker Speech Recognition with Source Localization
Paper and Code
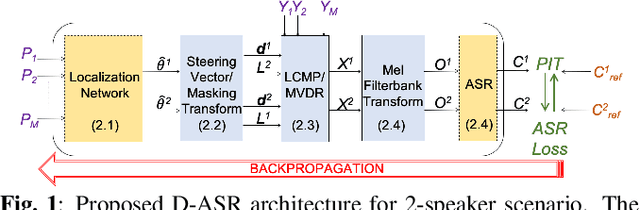
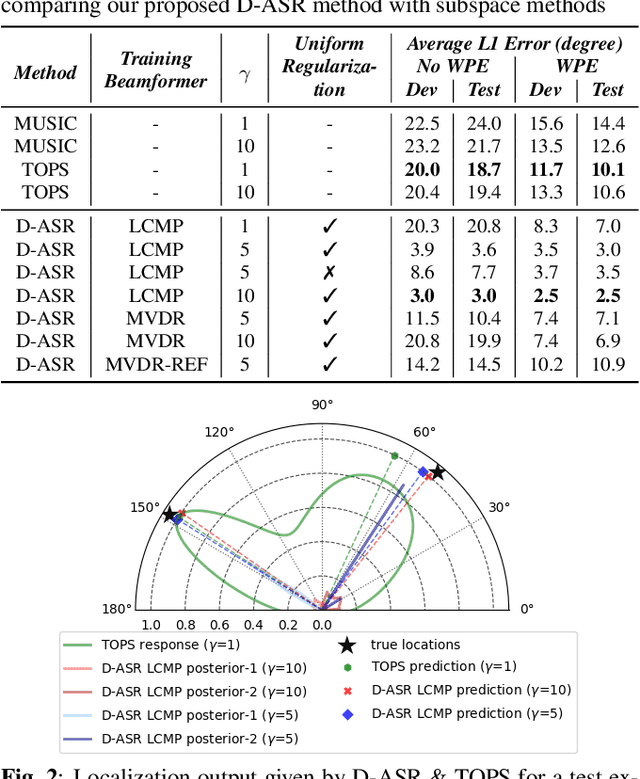

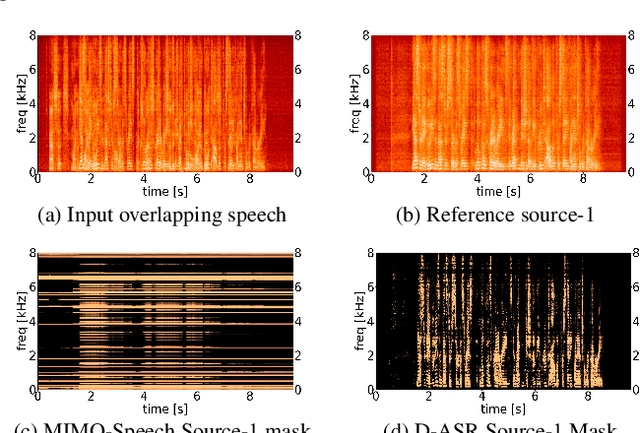
This paper proposes a new paradigm for handling far-field multi-speaker data in an end-to-end neural network manner, called directional automatic speech recognition (D-ASR), which explicitly models source speaker locations. In D-ASR, the azimuth angle of the sources with respect to the microphone array is defined as a latent variable. This angle controls the quality of separation, which in turn determines the ASR performance. All three functionalities of D-ASR: localization, separation, and recognition are connected as a single differentiable neural network and trained solely based on ASR error minimization objectives. The advantages of D-ASR over existing methods are threefold: (1) it provides explicit speaker locations, (2) it improves the explainability factor, and (3) it achieves better ASR performance as the process is more streamlined. In addition, D-ASR does not require explicit direction of arrival (DOA) supervision like existing data-driven localization models, which makes it more appropriate for realistic data. For the case of two source mixtures, D-ASR achieves an average DOA prediction error of less than three degrees. It also outperforms a strong far-field multi-speaker end-to-end system in both separation quality and ASR performance.