 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy for Text Analytics via Natural Text Sanitization
Paper and Code
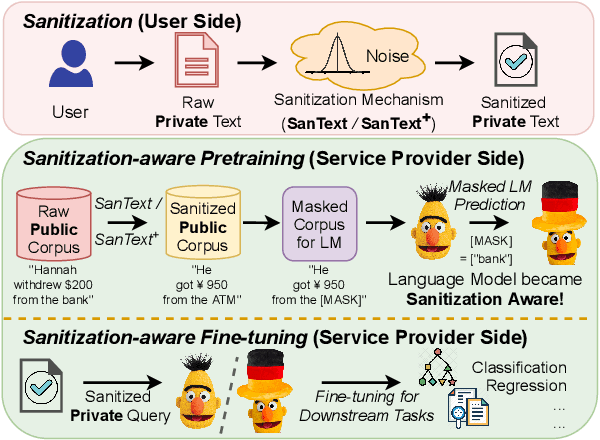
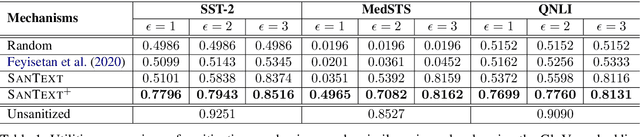

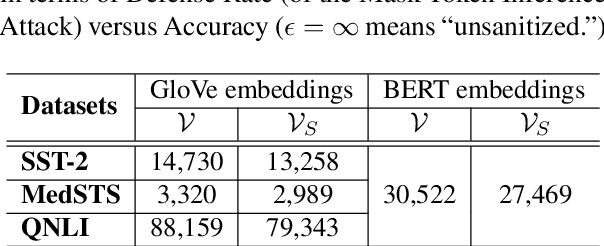
Texts convey sophisticated knowledge. However, texts also convey sensitive information. Despite the success of general-purpose language models and domain-specific mechanisms with differential privacy (DP), existing text sanitization mechanisms still provide low utility, as cursed by the high-dimensional text representation. The companion issue of utilizing sanitized texts for downstream analytics is also under-explored. This paper takes a direct approach to text sanitization. Our insight is to consider both sensitivity and similarity via our new local DP notion. The sanitized texts also contribute to our sanitization-aware pretraining and fine-tuning, enabling privacy-preserving natural language processing over the BERT language model with promising utility. Surprisingly, the high utility does not boost up the success rate of inference attacks.