 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFTR: Depth-supervised Fusion Transformer for Salient Object Detection
Paper and Code
Apr 11, 2022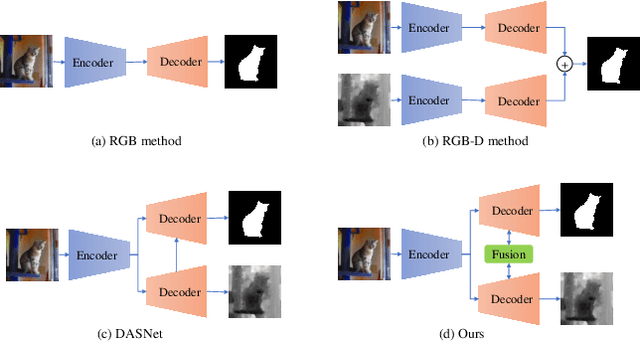
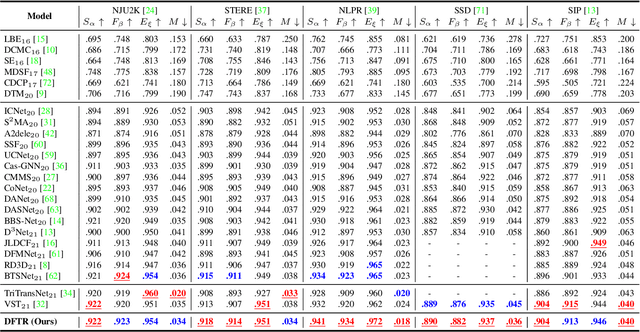
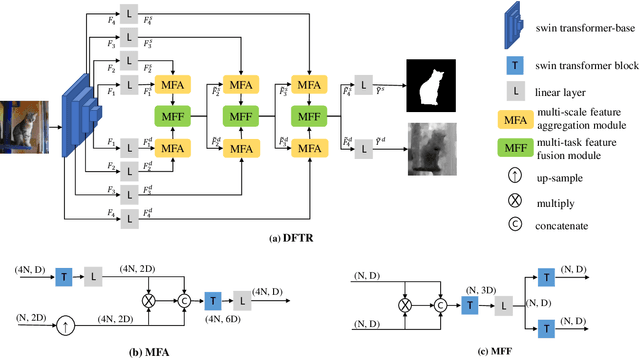
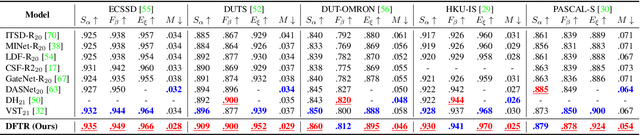
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. By reformulating the depth information as supervision rather than as input, depth-supervised convolutional neural networks (CNN) have achieved promising results on both RGB and RGB-D SOD scenarios with the merits of no requirements for extra depth networks and depth inputs in the inference stage. This paper, for the first time, seeks to expand the applicability of depth supervision to the Transformer architecture. Specifically, we develop a Depth-supervised Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary features: 1) DFTR, to the best of our knowledge, is the first pure Transformer-based model for depth-supervised SOD; 2) A multi-scale feature aggregation (MFA) module is proposed to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) To enable bidirectional information flow across different streams of features, a novel multi-stage feature fusion (MFF) module is further integrated into our DFTR with the emphasis on salient regions at different network learning stages. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be made publicly available.