 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Understanding Generalization Barriers for Neural Machine Translation
Paper and Code
Apr 05, 2020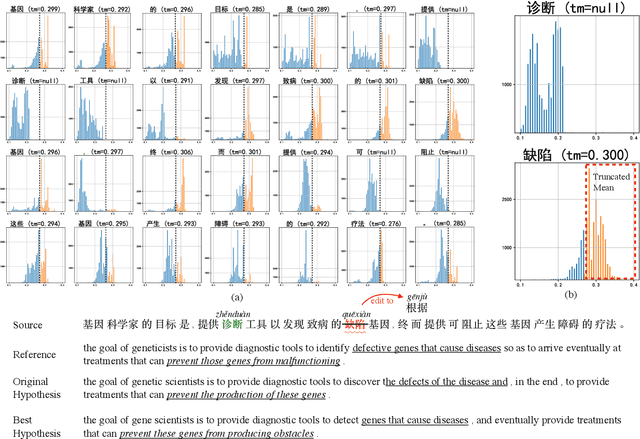

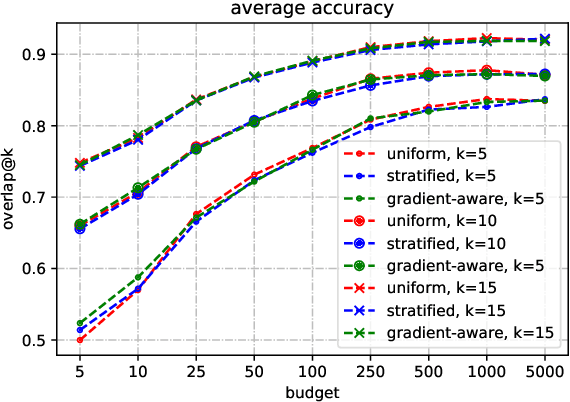

Generalization to unseen instances is our eternal pursuit for all data-driven models. However, for realistic task like machine translation, the traditional approach measuring generalization in an average sense provides poor understanding for the fine-grained generalization ability. As a remedy, this paper attempts to identify and understand generalization barrier words within an unseen input sentence that \textit{cause} the degradation of fine-grained generalization. We propose a principled definition of generalization barrier words and a modified version which is tractable in computation. Based on the modified one, we propose three simple methods for barrier detection by the search-aware risk estimation through counterfactual generation. We then conduct extensive analyses on those detected generalization barrier words on both Zh$\Leftrightarrow$En NIST benchmarks from various perspectives. Potential usage of the detected barrier words is also discussed.