 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFLOCNet: Deep Image Editing via Flexible Low-level Controls
Paper and Code
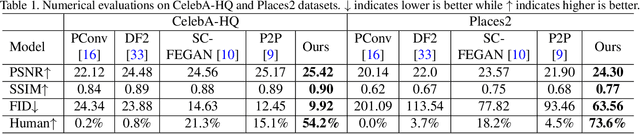
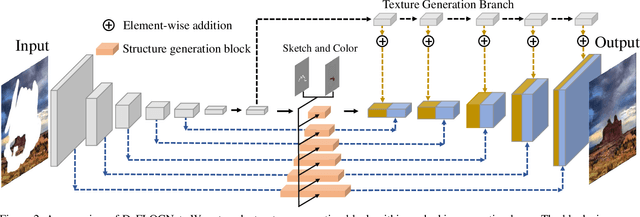
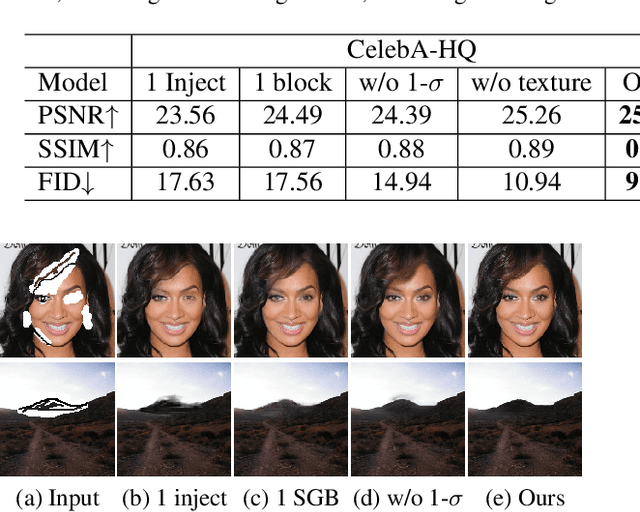
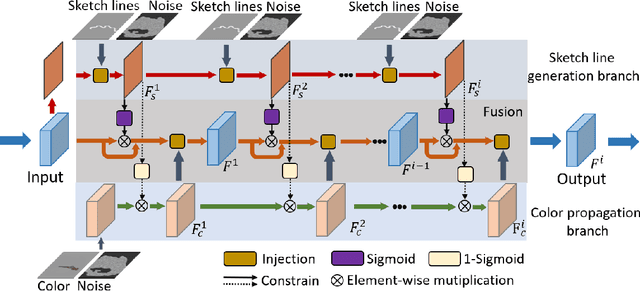
User-intended visual content fills the hole regions of an input image in the image editing scenario. The coarse low-level inputs, which typically consist of sparse sketch lines and color dots, convey user intentions for content creation (\ie, free-form editing). While existing methods combine an input image and these low-level controls for CNN inputs, the corresponding feature representations are not sufficient to convey user intentions, leading to unfaithfully generated content. In this paper, we propose DeFLOCNet which relies on a deep encoder-decoder CNN to retain the guidance of these controls in the deep feature representations. In each skip-connection layer, we design a structure generation block. Instead of attaching low-level controls to an input image, we inject these controls directly into each structure generation block for sketch line refinement and color propagation in the CNN feature space. We then concatenate the modulated features with the original decoder features for structure generation. Meanwhile, DeFLOCNet involves another decoder branch for texture generation and detail enhancement. Both structures and textures are rendered in the decoder, leading to user-intended editing results. Experiments on benchmarks demonstrate that DeFLOCNet effectively transforms different user intentions to create visually pleasing content.