 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Video-Based Performance Cloning
Paper and Code
Aug 21, 2018
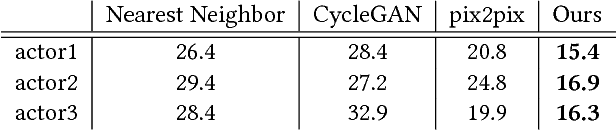
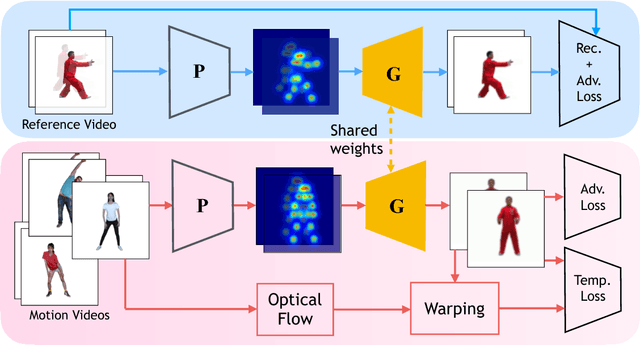

We present a new video-based performance cloning technique. After training a deep generative network using a reference video capturing the appearance and dynamics of a target actor, we are able to generate videos where this actor reenacts other performances. All of the training data and the driving performances are provided as ordinary video segments, without motion capture or depth information. Our generative model is realized as a deep neural network with two branches, both of which train the same space-time conditional generator, using shared weights. One branch, responsible for learning to generate the appearance of the target actor in various poses, uses \emph{paired} training data, self-generated from the reference video. The second branch uses unpaired data to improve generation of temporally coherent video renditions of unseen pose sequences. We demonstrate a variety of promising results, where our method is able to generate temporally coherent videos, for challenging scenarios where the reference and driving videos consist of very different dance performances. Supplementary video: https://youtu.be/JpwsEeqNhhA.