 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Physics-aware Inference of Cloth Deformation for Monocular Human Performance Capture
Paper and Code
Nov 25, 2020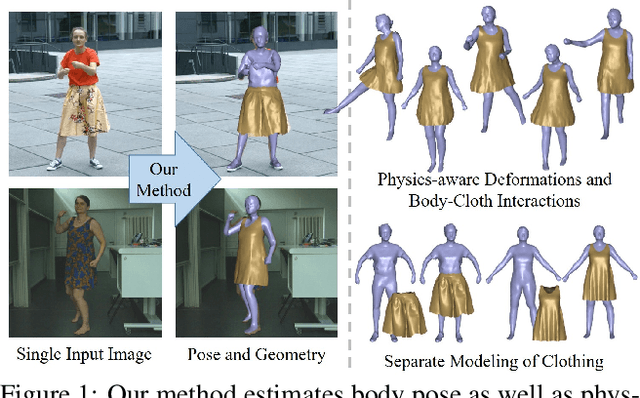



Recent monocular human performance capture approaches have shown compelling dense tracking results of the full body from a single RGB camera. However, existing methods either do not estimate clothing at all or model cloth deformation with simple geometric priors instead of taking into account the underlying physical principles. This leads to noticeable artifacts in their reconstructions, such as baked-in wrinkles, implausible deformations that seemingly defy gravity, and intersections between cloth and body. To address these problems, we propose a person-specific, learning-based method that integrates a finite element-based simulation layer into the training process to provide for the first time physics supervision in the context of weakly-supervised deep monocular human performance capture. We show how integrating physics into the training process improves the learned cloth deformations, allows modeling clothing as a separate piece of geometry, and largely reduces cloth-body intersections. Relying only on weak 2D multi-view supervision during training, our approach leads to a significant improvement over current state-of-the-art methods and is thus a clear step towards realistic monocular capture of the entire deforming surface of a clothed human.