 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Depth Inference using Binocular and Monocular Cues
Paper and Code
Aug 06, 2018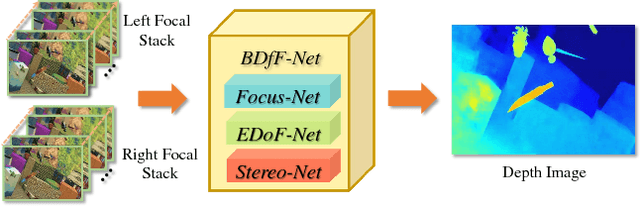



Human visual system relies on both binocular stereo cues and monocular focusness cues to gain effective 3D perception. In computer vision, the two problems are traditionally solved in separate tracks. In this paper, we present a unified learning-based technique that simultaneously uses both types of cues for depth inference. Specifically, we use a pair of focal stacks as input to emulate human perception. We first construct a comprehensive focal stack training dataset synthesized by depth-guided light field rendering. We then construct three individual networks: a FocusNet to extract depth from a single focal stack, a EDoFNet to obtain the extended depth of field (EDoF) image from the focal stack, and a StereoNet to conduct stereo matching. We then integrate them into a unified solution to obtain high quality depth maps. Comprehensive experiments show that our approach outperforms the state-of-the-art in both accuracy and speed and effectively emulates human vision systems.