 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd Counting via Weighted VLAD on Dense Attribute Feature Maps
Paper and Code
Apr 29, 2016
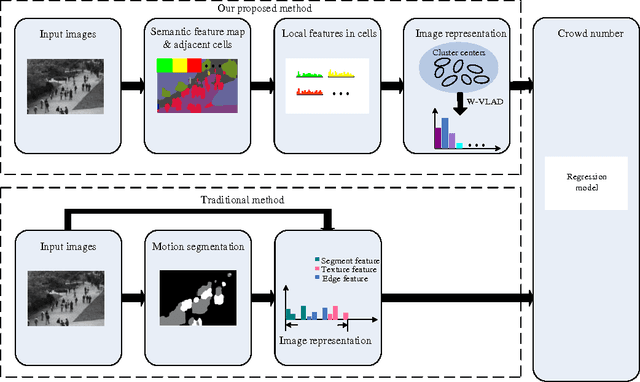
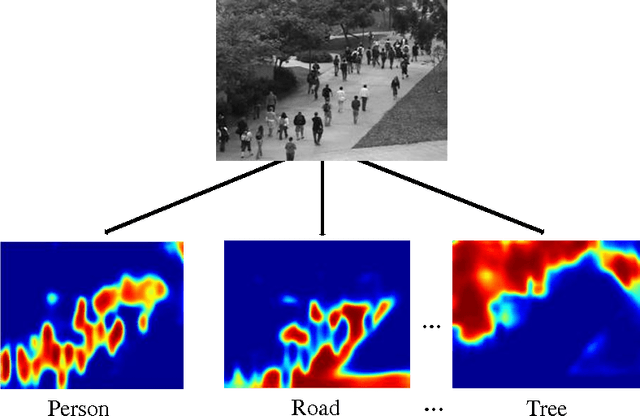
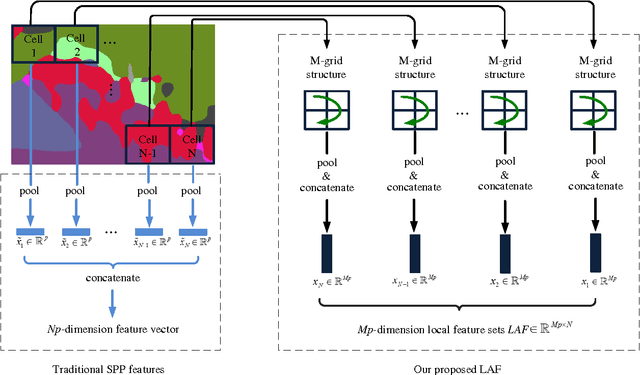
Crowd counting is an important task in computer vision, which has many applications in video surveillance. Although the regression-based framework has achieved great improvements for crowd counting, how to improve the discriminative power of image representation is still an open problem. Conventional holistic features used in crowd counting often fail to capture semantic attributes and spatial cues of the image. In this paper, we propose integrating semantic information into learning locality-aware feature sets for accurate crowd counting. First, with the help of convolutional neural network (CNN), the original pixel space is mapped onto a dense attribute feature map, where each dimension of the pixel-wise feature indicates the probabilistic strength of a certain semantic class. Then, locality-aware features (LAF) built on the idea of spatial pyramids on neighboring patches are proposed to explore more spatial context and local information. Finally, the traditional VLAD encoding method is extended to a more generalized form in which diverse coefficient weights are taken into consideration. Experimental results validate the effectiveness of our presented method.