 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Visual Matching via Generalized Similarity Measure and Feature Learning
Paper and Code
May 13, 2016
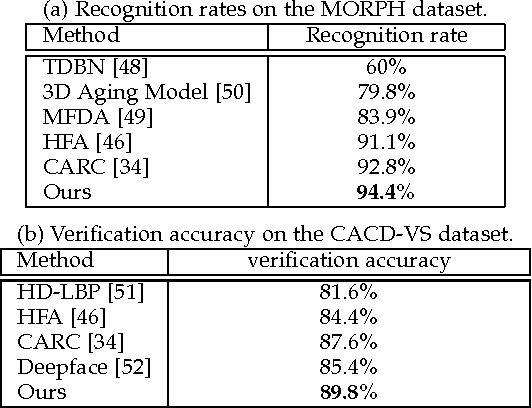


Cross-domain visual data matching is one of the fundamental problems in many real-world vision tasks, e.g., matching persons across ID photos and surveillance videos. Conventional approaches to this problem usually involves two steps: i) projecting samples from different domains into a common space, and ii) computing (dis-)similarity in this space based on a certain distance. In this paper, we present a novel pairwise similarity measure that advances existing models by i) expanding traditional linear projections into affine transformations and ii) fusing affine Mahalanobis distance and Cosine similarity by a data-driven combination. Moreover, we unify our similarity measure with feature representation learning via deep convolutional neural networks. Specifically, we incorporate the similarity measure matrix into the deep architecture, enabling an end-to-end way of model optimization. We extensively evaluate our generalized similarity model in several challenging cross-domain matching tasks: person re-identification under different views and face verification over different modalities (i.e., faces from still images and videos, older and younger faces, and sketch and photo portraits). The experimental results demonstrate superior performance of our model over other state-of-the-art methods.