 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Function-Dependent Barren Plateaus in Shallow Quantum Neural Networks
Paper and Code
Feb 04, 2020
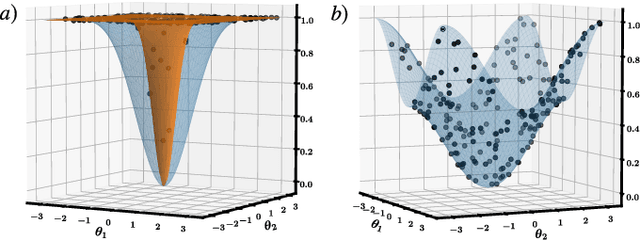

Variational quantum algorithms (VQAs) optimize the parameters $\boldsymbol{\theta}$ of a quantum neural network $V(\boldsymbol{\theta})$ to minimize a cost function $C$. While VQAs may enable practical applications of noisy quantum computers, they are nevertheless heuristic methods with unproven scaling. Here, we rigorously prove two results, assuming $V(\boldsymbol{\theta})$ is a hardware-efficient ansatz composed of blocks forming local 2-designs. Our first result states that defining $C$ in terms of global observables leads to an exponentially vanishing gradient (i.e., a barren plateau) even when $V(\boldsymbol{\theta})$ is shallow. This implies that several VQAs in the literature must revise their proposed cost functions. On the other hand, our second result states that defining $C$ with local observables leads to at worst a polynomially vanishing gradient, so long as the depth of $V(\boldsymbol{\theta})$ is $\mathcal{O}(\log n)$. Taken together, our results establish a connection between locality and trainability. Finally, we illustrate these ideas with large-scale simulations, up to 100 qubits, of a particular VQA known as quantum autoencoders.