 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Analysis of Homotopy-SGD for non-convex optimization
Paper and Code
Nov 20, 2020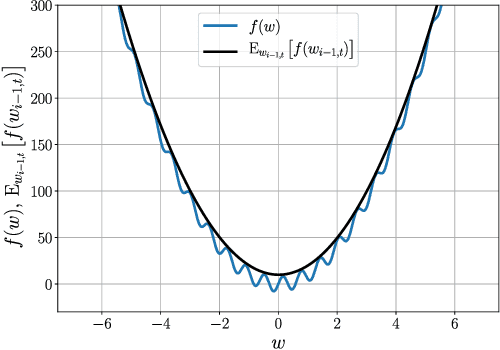
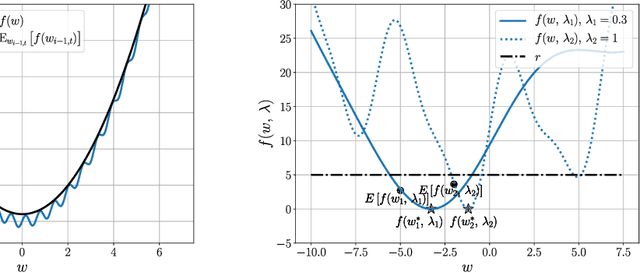
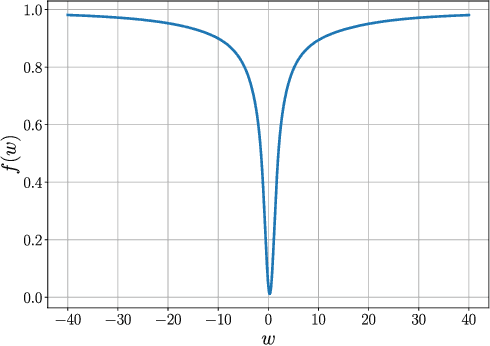

First-order stochastic methods for solving large-scale non-convex optimization problems are widely used in many big-data applications, e.g. training deep neural networks as well as other complex and potentially non-convex machine learning models. Their inexpensive iterations generally come together with slow global convergence rate (mostly sublinear), leading to the necessity of carrying out a very high number of iterations before the iterates reach a neighborhood of a minimizer. In this work, we present a first-order stochastic algorithm based on a combination of homotopy methods and SGD, called Homotopy-Stochastic Gradient Descent (H-SGD), which finds interesting connections with some proposed heuristics in the literature, e.g. optimization by Gaussian continuation, training by diffusion, mollifying networks. Under some mild assumptions on the problem structure, we conduct a theoretical analysis of the proposed algorithm. Our analysis shows that, with a specifically designed scheme for the homotopy parameter, H-SGD enjoys a global linear rate of convergence to a neighborhood of a minimum while maintaining fast and inexpensive iterations. Experimental evaluations confirm the theoretical results and show that H-SGD can outperform standard SGD.