 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlLLM: Augment Language Models with Tools by Searching on Graphs
Paper and Code


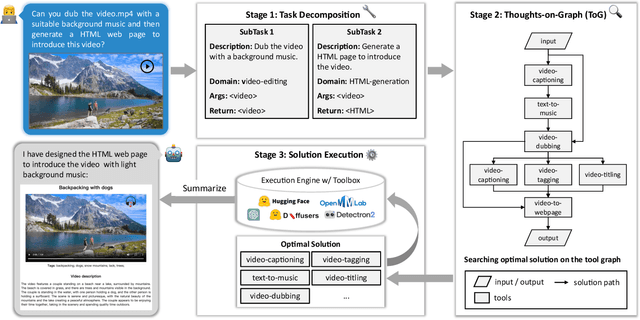

We present ControlLLM, a novel framework that enables large language models (LLMs) to utilize multi-modal tools for solving complex real-world tasks. Despite the remarkable performance of LLMs, they still struggle with tool invocation due to ambiguous user prompts, inaccurate tool selection and parameterization, and inefficient tool scheduling. To overcome these challenges, our framework comprises three key components: (1) a \textit{task decomposer} that breaks down a complex task into clear subtasks with well-defined inputs and outputs; (2) a \textit{Thoughts-on-Graph (ToG) paradigm} that searches the optimal solution path on a pre-built tool graph, which specifies the parameter and dependency relations among different tools; and (3) an \textit{execution engine with a rich toolbox} that interprets the solution path and runs the tools efficiently on different computational devices. We evaluate our framework on diverse tasks involving image, audio, and video processing, demonstrating its superior accuracy, efficiency, and versatility compared to existing methods. The code is at https://github.com/OpenGVLab/ControlLLM .