 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Fitted Value Iteration for Robust Policies
Paper and Code
Oct 05, 2021
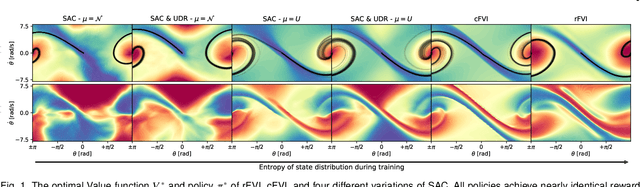


Solving the Hamilton-Jacobi-Bellman equation is important in many domains including control, robotics and economics. Especially for continuous control, solving this differential equation and its extension the Hamilton-Jacobi-Isaacs equation, is important as it yields the optimal policy that achieves the maximum reward on a give task. In the case of the Hamilton-Jacobi-Isaacs equation, which includes an adversary controlling the environment and minimizing the reward, the obtained policy is also robust to perturbations of the dynamics. In this paper we propose continuous fitted value iteration (cFVI) and robust fitted value iteration (rFVI). These algorithms leverage the non-linear control-affine dynamics and separable state and action reward of many continuous control problems to derive the optimal policy and optimal adversary in closed form. This analytic expression simplifies the differential equations and enables us to solve for the optimal value function using value iteration for continuous actions and states as well as the adversarial case. Notably, the resulting algorithms do not require discretization of states or actions. We apply the resulting algorithms to the Furuta pendulum and cartpole. We show that both algorithms obtain the optimal policy. The robustness Sim2Real experiments on the physical systems show that the policies successfully achieve the task in the real-world. When changing the masses of the pendulum, we observe that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi