 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Temporal Relationship for Action Localization
Paper and Code
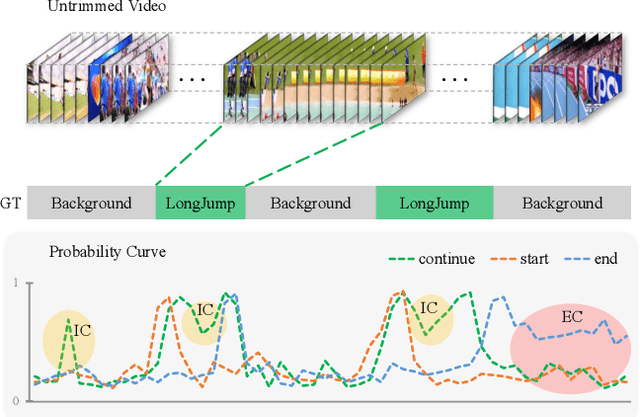


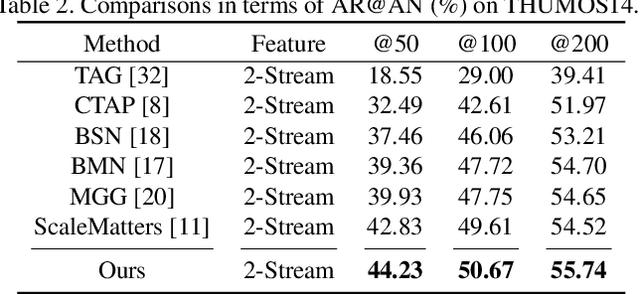
Recently, temporal action localization (TAL), i.e., finding specific action segments in untrimmed videos, has attracted increasing attentions of the computer vision community. State-of-the-art solutions for TAL involves predicting three values at each time point, corresponding to the probabilities that the action starts, continues and ends, and post-processing these curves for the final localization. This paper delves deep into this mechanism, and argues that existing approaches mostly ignored the potential relationship of these curves, and results in low quality of action proposals. To alleviate this problem, we add extra constraints to these curves, e.g., the probability of ''action continues'' should be relatively high between probability peaks of ''action starts'' and ''action ends'', so that the entire framework is aware of these latent constraints during an end-to-end optimization process. Experiments are performed on two popular TAL datasets, THUMOS14 and ActivityNet1.3. Our approach clearly outperforms the baseline both quantitatively (in terms of the AR@AN and mAP) and qualitatively (the curves in the testing stage become much smoother). In particular, when we build our constraints beyond TSA-Net and PGCN, we achieve the state-of-the-art performance especially at strict high IoU settings. The code will be available.