 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnections between Numerical Algorithms for PDEs and Neural Networks
Paper and Code
Jul 30, 2021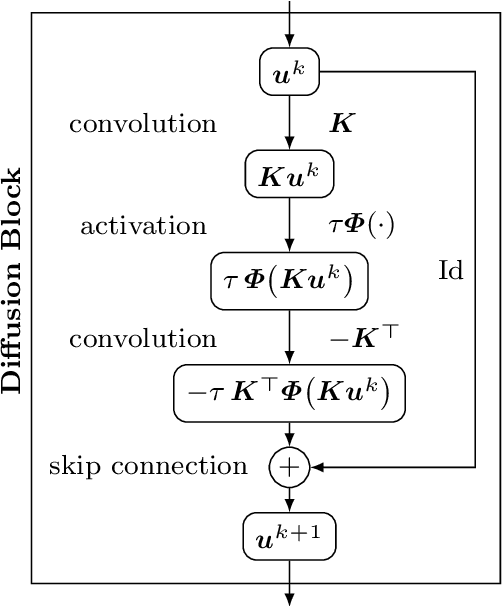
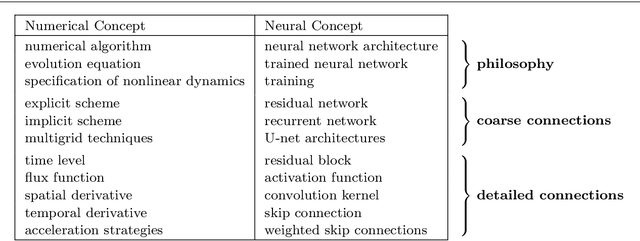
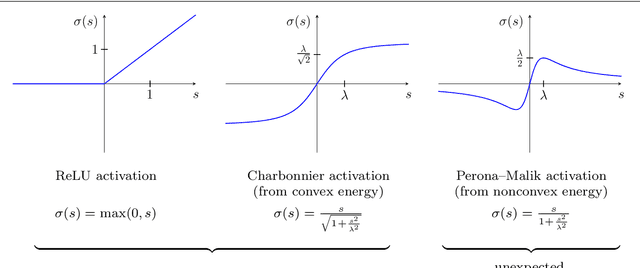
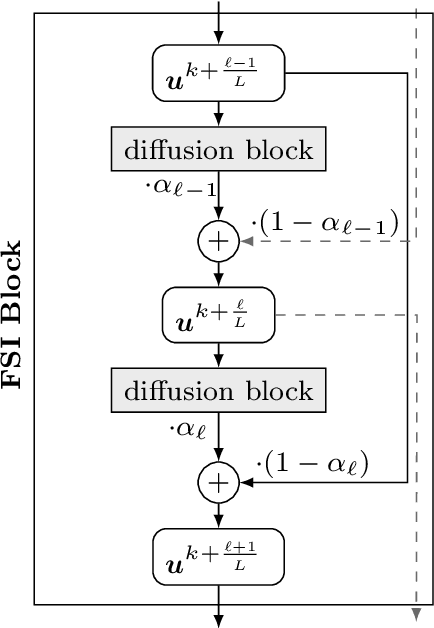
We investigate numerous structural connections between numerical algorithms for partial differential equations (PDEs) and neural architectures. Our goal is to transfer the rich set of mathematical foundations from the world of PDEs to neural networks. Besides structural insights we provide concrete examples and experimental evaluations of the resulting architectures. Using the example of generalised nonlinear diffusion in 1D, we consider explicit schemes, acceleration strategies thereof, implicit schemes, and multigrid approaches. We connect these concepts to residual networks, recurrent neural networks, and U-net architectures. Our findings inspire a symmetric residual network design with provable stability guarantees and justify the effectiveness of skip connections in neural networks from a numerical perspective. Moreover, we present U-net architectures that implement multigrid techniques for learning efficient solutions of partial differential equation models, and motivate uncommon design choices such as trainable nonmonotone activation functions. Experimental evaluations show that the proposed architectures save half of the trainable parameters and can thus outperform standard ones with the same model complexity. Our considerations serve as a basis for explaining the success of popular neural architectures and provide a blueprint for developing new mathematically well-founded neural building blocks.