 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfined Gradient Descent: Privacy-preserving Optimization for Federated Learning
Paper and Code
Apr 27, 2021

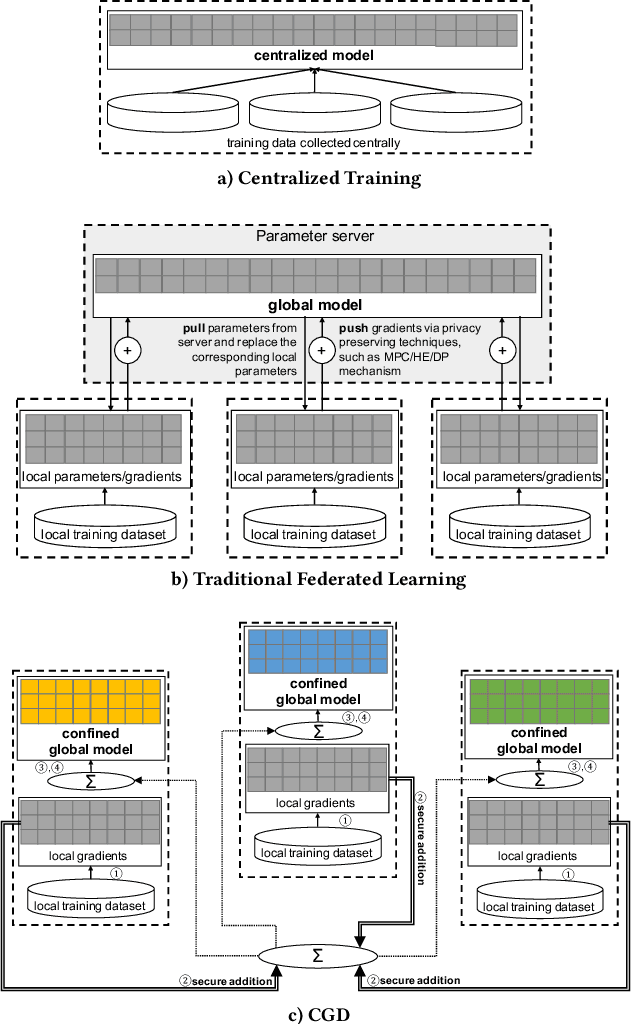

Federated learning enables multiple participants to collaboratively train a model without aggregating the training data. Although the training data are kept within each participant and the local gradients can be securely synthesized, recent studies have shown that such privacy protection is insufficient. The global model parameters that have to be shared for optimization are susceptible to leak information about training data. In this work, we propose Confined Gradient Descent (CGD) that enhances privacy of federated learning by eliminating the sharing of global model parameters. CGD exploits the fact that a gradient descent optimization can start with a set of discrete points and converges to another set at the neighborhood of the global minimum of the objective function. It lets the participants independently train on their local data, and securely share the sum of local gradients to benefit each other. We formally demonstrate CGD's privacy enhancement over traditional FL. We prove that less information is exposed in CGD compared to that of traditional FL. CGD also guarantees desired model accuracy. We theoretically establish a convergence rate for CGD. We prove that the loss of the proprietary models learned for each participant against a model learned by aggregated training data is bounded. Extensive experimental results on two real-world datasets demonstrate the performance of CGD is comparable with the centralized learning, with marginal differences on validation loss (mostly within 0.05) and accuracy (mostly within 1%).