 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Feedback Discriminative Propagation for Video Super-Resolution
Paper and Code
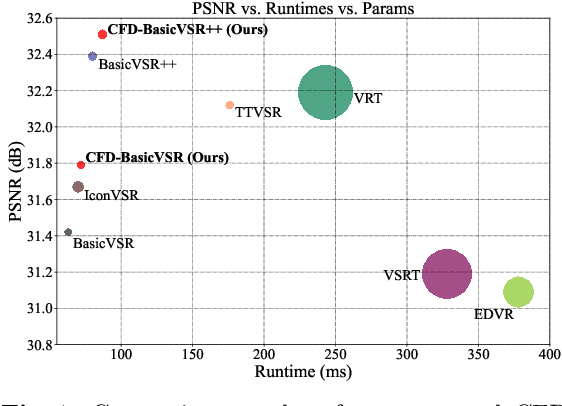
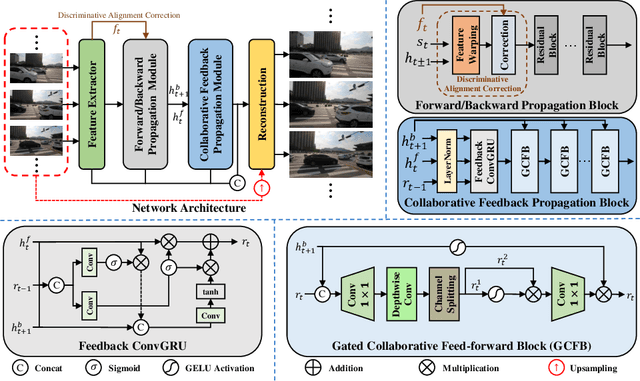
The key success of existing video super-resolution (VSR) methods stems mainly from exploring spatial and temporal information, which is usually achieved by a recurrent propagation module with an alignment module. However, inaccurate alignment usually leads to aligned features with significant artifacts, which will be accumulated during propagation and thus affect video restoration. Moreover, propagation modules only propagate the same timestep features forward or backward that may fail in case of complex motion or occlusion, limiting their performance for high-quality frame restoration. To address these issues, we propose a collaborative feedback discriminative (CFD) method to correct inaccurate aligned features and model long -range spatial and temporal information for better video reconstruction. In detail, we develop a discriminative alignment correction (DAC) method to adaptively explore information and reduce the influences of the artifacts caused by inaccurate alignment. Then, we propose a collaborative feedback propagation (CFP) module that employs feedback and gating mechanisms to better explore spatial and temporal information of different timestep features from forward and backward propagation simultaneously. Finally, we embed the proposed DAC and CFP into commonly used VSR networks to verify the effectiveness of our method. Quantitative and qualitative experiments on several benchmarks demonstrate that our method can improve the performance of existing VSR models while maintaining a lower model complexity. The source code and pre-trained models will be available at \url{https://github.com/House-Leo/CFDVSR}.