 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLAM: Co-Learning of Deep Neural Networks and Soft Labels via Alternating Minimization
Paper and Code
Apr 26, 2020


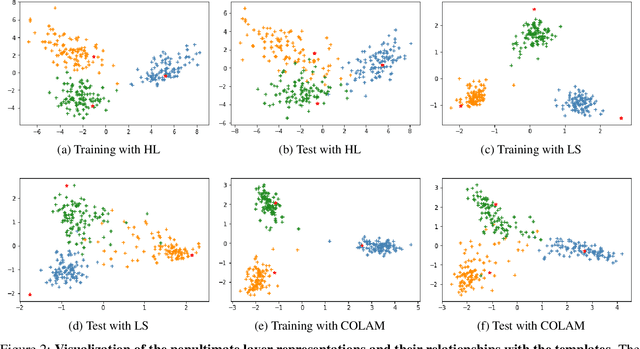
Softening labels of training datasets with respect to data representations has been frequently used to improve the training of deep neural networks (DNNs). While such a practice has been studied as a way to leverage privileged information about the distribution of the data, a well-trained learner with soft classification outputs should be first obtained as a prior to generate such privileged information. To solve such chicken-egg problem, we propose COLAM framework that Co-Learns DNNs and soft labels through Alternating Minimization of two objectives - (a) the training loss subject to soft labels and (b) the objective to learn improved soft labels - in one end-to-end training procedure. We performed extensive experiments to compare our proposed method with a series of baselines. The experiment results show that COLAM achieves improved performance on many tasks with better testing classification accuracy. We also provide both qualitative and quantitative analyses that explain why COLAM works well.