 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Meets Implicit Generative Models
Paper and Code
Aug 02, 2018
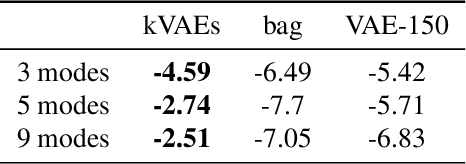
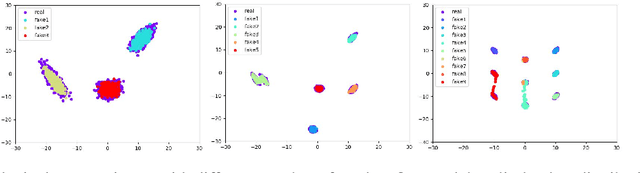

Clustering is a cornerstone of unsupervised learning which can be thought as disentangling the multiple generative mechanisms underlying the data. In this paper we introduce an algorithmic framework to train mixtures of implicit generative models which we instantiate for variational autoencoders. Relying on an additional set of discriminators, we propose a competitive procedure in which the models only need to approximate the portion of the data distribution from which they can produce realistic samples. As a byproduct, each model is simpler to train, and a clustering interpretation arises naturally from the partitioning of the training points among the models. We empirically show that our approach splits the training distribution in a reasonable way and increases the quality of the generated samples.