 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Understanding the Generalization Error of Transfer Learning with Gibbs Algorithm
Paper and Code
Nov 02, 2021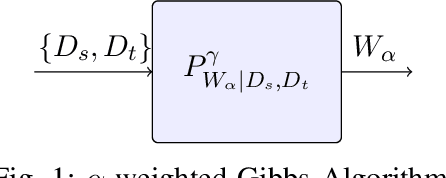
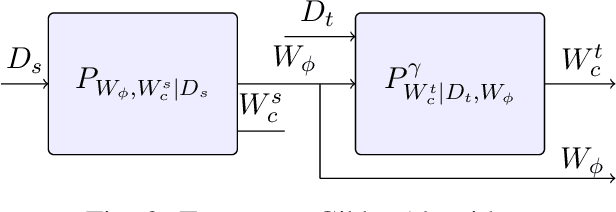


We provide an information-theoretic analysis of the generalization ability of Gibbs-based transfer learning algorithms by focusing on two popular transfer learning approaches, $\alpha$-weighted-ERM and two-stage-ERM. Our key result is an exact characterization of the generalization behaviour using the conditional symmetrized KL information between the output hypothesis and the target training samples given the source samples. Our results can also be applied to provide novel distribution-free generalization error upper bounds on these two aforementioned Gibbs algorithms. Our approach is versatile, as it also characterizes the generalization errors and excess risks of these two Gibbs algorithms in the asymptotic regime, where they converge to the $\alpha$-weighted-ERM and two-stage-ERM, respectively. Based on our theoretical results, we show that the benefits of transfer learning can be viewed as a bias-variance trade-off, with the bias induced by the source distribution and the variance induced by the lack of target samples. We believe this viewpoint can guide the choice of transfer learning algorithms in practice.