 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAA : Channelized Axial Attention for Semantic Segmentation
Paper and Code

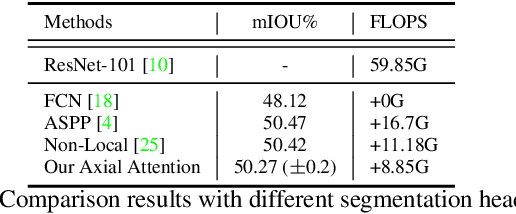
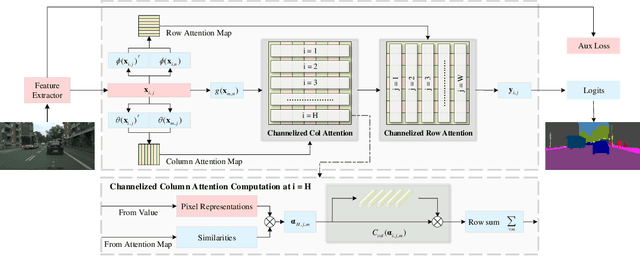
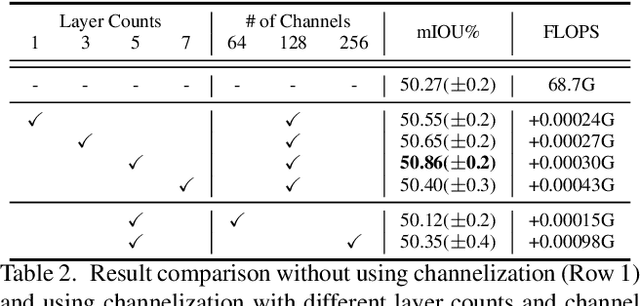
Self-attention and channel attention, modelling the semantic interdependencies in spatial and channel dimensions respectively, have recently been widely used for semantic segmentation. However, computing self-attention and channel attention separately and then fusing them directly can cause conflicting feature representations. In this paper, we propose the Channelized Axial Attention (CAA) to seamlessly integrate channel attention and axial attention with reduced computational complexity. After computing axial attention maps, we propose to channelize the intermediate results obtained from the transposed dot-product so that the channel importance of each axial representation is optimized across the whole receptive field. We further develop grouped vectorization, which allows our model to be run in the very limited GPU memory with a speed comparable with full vectorization. Comparative experiments conducted on multiple benchmark datasets, including Cityscapes, PASCAL Context and COCO-Stuff, demonstrate that our CAA not only requires much less computation resources but also outperforms the state-of-the-art segmentation models based on ResNet-101 on all tested datasets.